Git으로 관리하는 LLM Wiki
목차
개인 지식베이스에서 어려운 부분은 검색이 아니라 승급 경계였다.
무엇을 저장할지보다, 무엇을 아직 답변 재료로 쓰면 안 되는지 구분하는 일이 먼저였다.
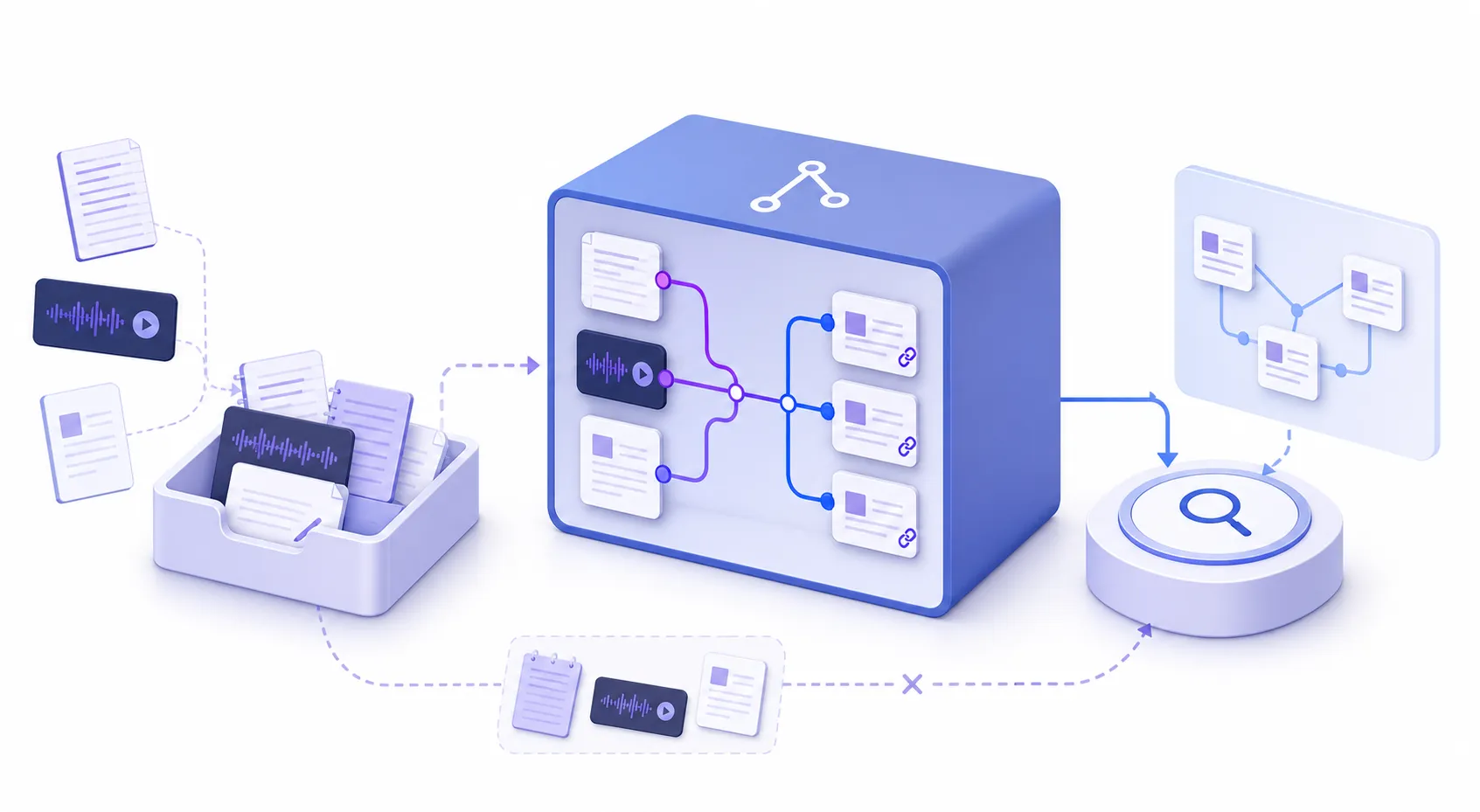
처음에는 단순하게 생각했다. 회의 메모, 웹에서 찾은 글, 작업 중 나온 판단, 음성 메모를 전사한 내용까지 한 폴더에 잘 넣어두면 나중에 LLM이 알아서 찾아주지 않을까. 이미 Markdown이고, Git으로 버전 관리도 되고, Obsidian으로 열 수도 있으니 개인 RAG 저장소로는 충분해 보였다.
그런데 실제 자료를 넣기 시작하자 바로 다른 문제가 보였다. 자료가 있다는 사실과, 그 자료를 다음 답변의 근거로 써도 된다는 판단은 다른 일이었다. 어떤 메모는 아직 확인 전이었고, 어떤 내용은 민감했고, 어떤 요약은 원문과 연결되어야 했다. 업무 맥락의 자료가 많을수록 이 차이는 더 커졌다.
앞선 글에서는 LLM Wiki를 RAG의 대안적 패턴으로 살펴봤다. 이번 글은 그 다음 이야기다. 패턴 자체가 아니라, 실제 내 저장소에 적용하면서 어디에 경계를 세웠고 왜 그렇게 했는지를 적는다.
그래서 지금 구성한 llm-wiki는 “많이 넣고 잘 검색하는 저장소”가 아니라 “아직 쓰면 안 되는 것과 재사용해도 되는 것을 분리하는 저장소”에 가깝다. LLM Wiki를 만든 이유도 여기에 있다. 답변 품질을 높이기 전에, 답변 재료의 자격을 다루고 싶었다.
LLM Wiki에서 raw를 바로 검색하지 않기로 했다
개인 지식베이스를 만들 때 가장 쉬운 길은 모든 입력을 한곳에 넣고 인덱싱하는 것이다. 웹 클립, 회의록, 음성 전사, 작업 메모, 채팅에서 건진 정보가 모두 chunk로 쪼개지고, 질문이 들어오면 비슷한 조각을 찾아 답한다.
이 방식은 빠르게 쓸 수 있다. 하지만 시간이 조금 지나면 세 가지가 섞인다.
- 내가 직접 확인한 사실
- 누군가의 발언이나 초안
- AI가 임시로 정리한 추정
LLM 입장에서는 셋 다 텍스트다. 하지만 운영하는 사람 입장에서는 전혀 다르다. 특히 업무 자료가 섞이면 “검색이 잘 된다”보다 “잘못 검색되지 않는다”가 더 중요해진다.
처음에 바꾼 판단은 여기였다. 원본을 없애지 않되, 원본을 곧바로 지식으로 취급하지 않는다. raw 자료는 보존하고, 그 위에 출처가 남은 요약을 만들고, 다시 그중에서 오래 재사용할 수 있는 판단만 context로 승급한다.
flowchart LR
A[입력<br>메모, 회의록, 웹 자료] --> B[inbox<br>아직 검토 전]
B --> C[sources<br>출처와 처리 결과]
C --> D[context<br>재사용 가능한 지식]
D --> E[retrieval<br>답변에 쓰는 코퍼스]
B -. 제외 .-> E
C -. 제한적 사용 .-> E이 구조에서 중요한 것은 폴더 이름 자체가 아니다. 같은 Markdown 파일이라도 “지금 어느 단계인가”가 달라야 한다는 점이다. inbox에 있는 문서는 다음 작업 후보일 뿐이고, sources는 증거와 처리 결과를 남기는 곳이며, context는 나중에 LLM이 답변의 재료로 써도 되는 지식이다.
inbox는 지식이 아니라 대기열이다
inbox를 처음부터 깔끔하게 만들고 싶은 유혹이 있었다. 새 자료가 들어오면 제목을 붙이고, 링크를 정리하고, 관련 문서를 연결하고, 태그도 달고 싶어진다. 하지만 그렇게 하면 검토 전 자료가 너무 그럴듯해진다.
그래서 inbox에는 힘을 덜 준다. 여기에는 “처리해야 할 후보”라는 사실만 충분하면 된다. 음성 메모라면 어떤 녹음인지, 언제 들어온 것인지, 처리 방식이 무엇인지 정도만 남긴다. 원본 오디오나 민감한 raw 내용은 Git에 무리하게 넣지 않는다.
이 결정은 생각보다 운영감을 바꿨다. 예전에는 새 자료가 생기면 “어디에 정리하지?”를 먼저 고민했다. 지금은 “이건 아직 inbox인가, sources까지 갈 수 있는가, context로 승급할 만큼 안정적인가”를 묻는다. 분류 기준이 폴더 취향이 아니라 재사용 가능성으로 바뀐 셈이다.
inbox를 지식으로 착각하지 않는 것이 첫 번째 안전장치였다.
sources에는 증거와 처리 이력을 남긴다
두 번째 층은 sources다. 여기에는 원문 자체를 모두 복제하려는 목적보다, 나중에 추적 가능한 증거를 남기는 목적이 크다. 어떤 입력에서 왔는지, 어떤 방식으로 처리했는지, 사람이 승인한 요약인지, 전체 전사본을 보관하기로 했는지 같은 정보가 중요하다.
이 층을 만들지 않으면 context 문서가 너무 쉽게 떠다닌다. 한 문서에 “앞으로는 A 방식으로 처리한다”는 규칙이 적혀 있어도, 그 판단이 어떤 자료에서 나왔는지 모르면 나중에 고치기 어렵다. 기억은 남지만 근거가 사라진다.
그래서 sources는 답변용 지식이라기보다 감사 가능한 발판이다. 재사용 가능한 문장은 context로 올라가되, 그 문장이 어디서 왔는지는 sources로 돌아갈 수 있어야 한다.
이때부터 frontmatter가 단순한 장식이 아니게 됐다. source_channel, workflow, artifact_stage, sensitivity, indexable 같은 필드는 사람이 보기 위한 메모이면서 동시에 에이전트가 다음 행동을 결정하는 제어면이 된다.
quality_level: L1
artifact_stage: source
source_channel: voice-memo
workflow: meeting-note
sensitivity: internal
indexable: false이런 메타데이터는 예쁘지 않다. 하지만 예쁜 노트보다 더 중요한 것은, 자동화가 이 파일을 함부로 검색 코퍼스에 넣지 않게 하는 것이다.
context는 작고 단단해야 한다
context는 이 저장소에서 가장 조심스럽게 다루는 층이다. 여기에는 원본을 길게 요약한 문서보다, 나중에 반복해서 써야 할 판단과 절차가 들어간다.
예를 들면 이런 종류다.
- Git 저장소를 canonical write path로 둔다.
- 모바일과 Obsidian은 읽기와 캡처에 사용하되, 최종 편집 경로로 삼지 않는다.
- raw 전사본은 기본 보관 대상이 아니며, 승인된 요약과 manifest를 우선 남긴다.
- 검색 인덱스는 검토된 context를 기본 코퍼스로 삼는다.
이 문장들은 특정 회의의 내용이 아니다. 시간이 지나도 작업 방식에 영향을 주는 규칙이다. 그래서 context로 승급할 수 있다.
반대로 “어떤 회의에서 누가 무엇을 말했다”는 문장은 대부분 context가 아니다. 원문이나 요약으로 남길 수는 있지만, 다음 질문에 일반 지식처럼 쓰이면 위험하다. 이 경계를 지키는 것이 LLM Wiki 운영의 대부분이었다.
기존 RAG 시스템에서는 이 구분을 retrieval policy나 metadata filter에서 해결하려고 한다. 내 경우에는 그보다 앞단에서 파일의 생애주기를 나누는 쪽이 더 맞았다. Markdown 파일을 사람이 직접 읽고 고칠 수 있어야 했고, Git diff로 변경 이유를 확인할 수 있어야 했기 때문이다.
Git과 Obsidian의 역할을 나눴다
한때는 Obsidian vault 자체를 중심으로 둘까 고민했다. 모바일에서 바로 열 수 있고, 링크와 그래프가 좋고, 사람이 읽기 편하다. 지식베이스라는 단어에는 Obsidian이 자연스럽게 붙는다.
하지만 canonical 경로로는 Git 저장소가 더 맞았다. 이유는 단순하다. LLM과 스크립트가 파일을 만들고 고치는 순간, 변경 이력과 rollback, 리뷰 가능한 diff가 필요했다. iCloud 동기화 폴더를 직접 작업 공간으로 쓰면 편하긴 하지만, 자동 생성 파일과 모바일 편집, 동기화 충돌이 같은 층에서 섞인다.
그래서 Obsidian은 저장소가 아니라 조작면으로 두었다. Git 저장소가 원본이고, Obsidian은 읽기와 리뷰, 모바일 캡처를 위한 mirror다. 모바일에서 쓴 메모도 곧바로 context가 되지 않는다. 다시 inbox로 들어와 같은 승급 절차를 지난다.
이 결정은 약간 불편하다. 모바일에서 본 내용을 바로 고치고 싶을 때도 있다. 하지만 불편함이 경계 역할을 한다. 어디서나 편집 가능한 위키는 매력적이지만, AI가 함께 쓰는 위키에서는 “누가 어떤 상태의 문서를 바꿨는가”가 더 중요했다.
AI에게 맡긴 일과 맡기지 않은 일
이 저장소에서 AI는 많은 일을 한다. 자료 후보를 찾고, source manifest를 만들고, 회의 노트를 정리하고, 중복되는 context를 찾아주고, frontmatter lint를 통과하도록 고친다.
하지만 최종 승급 판단까지 완전히 맡기지는 않았다. AI는 정리와 제안을 잘하지만, 어떤 내용을 앞으로의 답변 재료로 써도 되는지는 사람이 봐야 한다. 특히 업무 자료가 섞인 저장소에서는 더 그렇다. 민감도는 텍스트 유사도만으로 판단되지 않고, 조직 맥락과 시간이 같이 작동한다.
그래서 workflow 문서도 코드만큼 중요해졌다. “이 요청이 들어오면 어떤 후보를 보여주고, 언제 원본을 건드리지 말고, 언제 transcript를 보관하지 말고, 어느 단계에서 lint를 돌리는가”를 문서화한다. 에이전트는 그 문서를 읽고 반복 가능한 작업자로 움직인다.
LLM Wiki를 만들면서 의외였던 점은, 지식 문서보다 운영 문서가 먼저 필요했다는 것이다. 좋은 답변을 만들려면 좋은 context가 필요하고, 좋은 context를 만들려면 좋은 intake 절차가 필요했다.
Git 기반 LLM Wiki가 남기는 비용
이 방식은 빠르지 않다. 모든 자료를 넣자마자 검색 가능한 상태로 만드는 것보다 단계가 많다. frontmatter도 써야 하고, source와 context를 나눠야 하고, 가끔은 mirror가 잘 갱신되는지도 봐야 한다.
또 하나의 비용은 판단 보류다. 어떤 자료는 당장 context로 올리고 싶지만, 아직 출처가 약하거나 민감도가 애매하면 inbox나 sources에 머문다. 검색 입장에서는 손해처럼 보인다. 하지만 장기적으로는 그 보류가 노이즈를 줄인다.
모든 개인 노트에 이 정도 구조가 필요한 것은 아니다. 읽은 글을 저장하고 가끔 검색하는 정도라면 폴더와 태그만으로도 충분하다. 이 방식은 AI 에이전트가 저장소를 읽고 다음 작업의 전제로 삼기 시작할 때, 그리고 raw 자료와 검토된 판단을 분리해야 할 때부터 값어치가 생긴다.
내가 이 구조를 택한 이유는 개인 지식베이스가 점점 “나 대신 기억하는 곳”이 되기 때문이다. 단순 검색 도구라면 조금 틀려도 다시 찾으면 된다. 하지만 에이전트가 이 저장소를 읽고 작업 방향을 바꾸기 시작하면, 잘못 승급된 지식은 다음 작업의 전제가 된다.
그래서 이 저장소에서 가장 중요한 명령은 ingest가 아니라 promotion이다.
지금의 판단
지금까지 구성한 LLM Wiki는 완성된 제품이라기보다 운영 규칙이 붙은 개인 지식 시스템에 가깝다. raw 자료를 많이 모으는 것보다, 어떤 자료를 아직 쓰지 않을지 표시하는 데 더 많은 설계가 들어갔다.
현재 기준으로 남은 판단은 세 가지다.
- Git이 canonical이어야 한다. AI가 파일을 바꾸는 순간 diff, commit, rollback이 지식 관리의 일부가 된다.
- Obsidian은 사람을 위한 조작면이어야 한다. 읽기, 링크 탐색, 모바일 캡처에는 좋지만 원본 편집 경로가 되면 경계가 흐려진다.
- retrieval은 context 이후의 문제다. 검색 품질을 고민하기 전에, 검색해도 되는 문서와 아직 안 되는 문서를 먼저 나눠야 한다.
나중에 retrieval layer를 붙이더라도 이 구조는 유지할 생각이다. LLM에게 더 많은 자료를 주는 것보다, 어떤 자료를 줄 수 있는 상태로 만들었는지 설명할 수 있는 편이 더 중요하기 때문이다.