LiteLLM으로 LLM API 통합하기 — 개인 인프라에서 엔터프라이즈까지
목차
프로젝트: BerriAI/litellm 최신 버전: v1.80.15-stable (2026년 1월) 라이센스: Open Core 모델
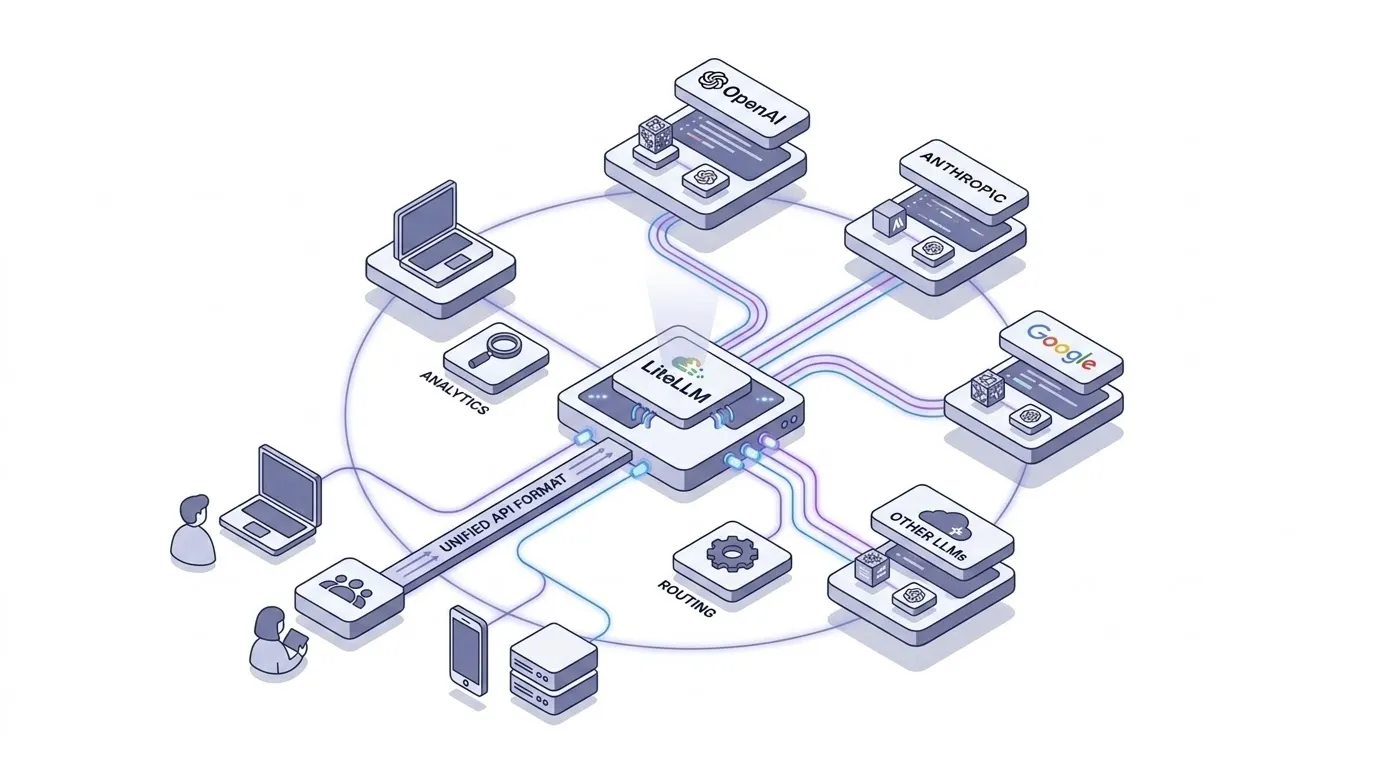
LiteLLM은 100개 이상의 LLM API를 OpenAI 형식으로 호출할 수 있는 오픈소스 AI Gateway이다.
LLM을 하나만 쓸 때는 간단하다. OpenAI API 키를 발급받고 openai.chat.completions.create()를 호출하면 끝이다.
문제는 두 번째 LLM을 추가할 때 시작된다. Claude를 쓰려면 Anthropic SDK를, Gemini를 쓰려면 Google SDK를 각각 설치해야 한다. 요청 형식이 다르고, 응답 구조가 다르고, 에러 코드가 다르다. 모델을 바꿀 때마다 코드를 고쳐야 한다.
LiteLLM은 이 문제에 대한 대답이다. 어떤 LLM이든 OpenAI SDK 형식 하나로 호출한다.
모델 이름만 바꾸면 된다
from litellm import completion
# OpenAI GPT-4
response = completion(model="gpt-4", messages=[{"role": "user", "content": "Hello"}])
# 같은 코드, 모델명만 변경 → Anthropic Claude
response = completion(model="claude-3-opus", messages=[{"role": "user", "content": "Hello"}])
# 같은 코드 → Google Gemini
response = completion(model="gemini-pro", messages=[{"role": "user", "content": "Hello"}])
# 같은 코드 → 로컬 Ollama
response = completion(model="ollama/llama3", messages=[{"role": "user", "content": "Hello"}])요청 형식, 응답 구조, 에러 핸들링, 스트리밍 방식이 모두 OpenAI 호환으로 통일된다. 지원하는 Provider는 100개 이상이다:
| 카테고리 | Provider |
|---|---|
| 클라우드 | OpenAI, Azure OpenAI, Anthropic, Google VertexAI, AWS Bedrock, Cohere |
| 오픈소스 | HuggingFace, VLLM, Ollama |
| 엔터프라이즈 | AWS Sagemaker, NVIDIA NIM |
| 기타 | Together.ai, Replicate, Groq |
이 통합 인터페이스가 LiteLLM의 본질이다. 나머지 기능은 모두 이 위에 얹힌 것이다.
SDK와 Proxy Server — 두 가지 배포 모델
LiteLLM은 두 가지로 쓸 수 있다. 상황에 따라 선택이 갈린다.
Python SDK: 라이브러리로 임베딩
pip install litellm애플리케이션 코드에 직접 넣는다. 서버를 따로 띄우지 않는다.
SDK에는 실전에서 중요한 기능이 들어있다:
- Router: GPT-4 호출이 실패하면 자동으로 Claude로 폴백. 여러 모델을 순서대로 시도하는 retry/fallback 체인
- Load Balancing: 같은 모델의 여러 API 키 또는 배포본에 부하를 분산. Rate limit 회피에 유용
- Cost Tracking: 모델별 토큰 단가를 내장하고 있어 호출마다 비용을 자동 계산
- Observability: Langfuse, MLflow, Lunary 등으로 로그를 보내는 콜백 내장
이럴 때 쓴다: 혼자 또는 소규모 팀. 인프라를 추가하고 싶지 않을 때. 개인 프로젝트.
Proxy Server: 중앙 집중 AI Gateway
docker run -p 4000:4000 \
-e DATABASE_URL=postgres://... \
-e REDIS_HOST=... \
ghcr.io/berriai/litellm:main-stable독립 프로세스다. 모든 LLM 호출이 이 게이트웨이를 경유한다. 클라이언트 입장에서는 OpenAI API를 호출하는 것과 동일하되, 엔드포인트 URL만 LiteLLM Proxy로 바꾸면 된다.
Gateway가 추가로 제공하는 것:
- Virtual Key: 실제 API 키를 숨기고, 팀/프로젝트별로 가상 키를 발급. 키 유출 위험 감소
- 예산 관리: 프로젝트별 월간 예산 한도. 초과하면 자동 차단
- 가드레일: 프롬프트 필터링, 응답 검증, 캐싱을 프로젝트별로 설정
- Admin Dashboard: 사용량, 비용, 에러율, 모델별 지연시간을 한눈에
이럴 때 쓴다: 여러 팀이 LLM을 쓰고, 비용 통제와 접근 관리가 필요할 때.
Gateway가 풀어주는 세 가지 문제
1. “이번 달 LLM 비용이 얼마야?”
이 질문에 답할 수 없다면 문제다. LLM 비용은 눈에 잘 안 보인다. 개발 단계에서는 작아 보이지만, 프로덕션에 올라가면 기하급수적으로 늘어난다. Gateway를 거치면 모든 호출의 비용이 프로젝트/사용자/모델별로 자동 기록된다.
2. “퇴사한 개발자가 API 키를 가지고 있다”
개발자마다 직접 API 키를 발급받으면 통제 불능이다. Gateway의 Virtual Key는 이 문제를 깔끔하게 해결한다. 실제 API 키는 Gateway에만 있고, 개발자는 Virtual Key를 사용한다. 퇴사? Virtual Key 폐기. 끝.
3. “GPT-4 대신 Claude를 써보고 싶은데, 코드를 다 고쳐야 한다”
Gateway 설정에서 모델 매핑만 바꾸면 된다. 클라이언트 코드는 건드리지 않는다. 더 나아가 A/B 테스트도 가능하다 — 트래픽의 50%를 GPT-4로, 50%를 Claude로 보내서 품질을 비교한다.
성능: Gateway 오버헤드는 무시할 수준
- P95 8ms @ 1,000 RPS
LLM API 호출 자체가 수 초에서 수십 초다. Gateway를 거쳐도 추가되는 지연이 8ms 수준이면 사실상 없는 것과 같다. -stable 태그 Docker 이미지는 12시간 부하 테스트를 통과한 검증된 빌드다.
Kubernetes에 올리기
프로덕션 배포에는 Kubernetes가 자연스럽다. LiteLLM은 Kubernetes manifest와 Terraform 템플릿을 공식으로 제공한다.
AWS 참조 아키텍처 예시:
LiteLLM Proxy (ECS/EKS, Autoscaling)
├── RDS (Postgres) — 설정, 사용자, 비용 데이터
├── ElastiCache (Redis) — 캐싱, Rate limiting
└── Cognito — SSO/인증 통합Self-hosted가 기본이다. 모든 데이터가 자기 인프라에 있으므로, 규제 산업이나 데이터 주권이 중요한 환경에 적합하다.
OpenAI 호환 엔드포인트
Gateway를 거치는 요청은 OpenAI API 형식 그대로다:
| 엔드포인트 | 용도 |
|---|---|
/chat/completions | 텍스트 생성 (핵심) |
/messages | Anthropic Messages API 호환 |
/embeddings | 벡터 임베딩 |
/image/generations | 이미지 생성 |
/audio/transcriptions | 음성→텍스트 |
/audio/speech | 텍스트→음성 |
/batches | 배치 처리 |
/rerank | 리랭킹 |
기존에 OpenAI SDK를 쓰고 있었다면, base URL만 LiteLLM Proxy로 바꾸면 된다.
2026년 최신 동향
v1.80.15-stable (2026년 1월) 기준 주목할 변화:
MCP Gateway가 가장 흥미롭다. Model Context Protocol 기반 도구에 대한 고정 엔드포인트를 제공하고, Key 및 Team별로 접근을 제어한다. AI 에이전트가 외부 도구를 호출할 때 Gateway가 관문 역할을 하는 것이다. LLM 호출뿐 아니라 도구 호출까지 중앙에서 관리하는 방향으로 진화하고 있다.
그 외:
- Manus API 통합 — 새로운 AI 에이전트 플랫폼 지원
- SSO Role Mapping — 엔터프라이즈 인증 강화
- Cost Estimator UI — 호출 전 비용 추정
주요 사용 기업으로는 Stripe, Google, Netflix가 있고, OpenAI Agents SDK도 내부적으로 LiteLLM을 LLM 라우팅 레이어로 사용한다.
솔직한 평가
좋은 점
- 통합 인터페이스: 100개 이상 LLM을 하나의 형식으로 — 이 부분은 경쟁 상대가 거의 없다
- OpenAI 호환: 기존 코드 마이그레이션 비용이 거의 제로
- Self-hosted: 데이터 주권을 포기하지 않아도 됨
- 오픈소스: Open Core 모델이지만 핵심 기능은 무료
주의할 점
- 800개 이상의 미해결 이슈 (2026년 1월 기준) — 특정 Provider에서 예상치 못한 동작을 만날 수 있다
- 인프라 부담: Proxy Server 운영에 Postgres + Redis가 필요
- 유료 기능: SSO, RBAC, 고급 가드레일은 Enterprise 라이선스
- 빠른 릴리스 주기: 버전 간 breaking change에 주의.
-stable태그를 쓰는 것이 안전하다
도입 판단 기준
| 상황 | 추천 |
|---|---|
| 혼자 개발, LLM 1-2개 | SDK로 충분 |
| 소규모 팀, 비용 추적 필요 | SDK의 Cost Tracking |
| 팀 3명+, 멀티 모델 | Proxy Server 도입 시점 |
| 엔터프라이즈, 거버넌스 필요 | Proxy Server + Enterprise |
“이번 달 LLM 비용이 얼마지?” — 이 질문이 나오면 Gateway를 도입할 때다.
# 가장 간단한 시작
pip install litellm
from litellm import completion
response = completion(model="gpt-4", messages=[{"role": "user", "content": "Hello!"}])여기서 시작해서, 필요에 따라 Gateway로 확장하면 된다.