LangGraph 핵심 컴포넌트 가이드: StateGraph부터 Checkpointer까지
목차
- LangChain이 해결하는 문제: LLM 호출의 표준화
- LangGraph가 해결하는 문제: 상태와 흐름 제어
- 대안 프레임워크와의 비교
- StateGraph: 그래프의 컨테이너
- Node: 실행의 최소 단위
- Edge: 노드 간 흐름 정의
- State 스키마와 Reducer: 데이터의 구조와 병합 규칙
- 병렬 실행: 정적 fan-out과 동적 Send
- Command: 상태 업데이트와 라우팅의 결합
- Checkpointer: 상태 영속화의 기반
- Thread와 Time Travel: 세션 격리와 상태 탐색
- interrupt와 Human-in-the-Loop: 실행 중단과 재개
- Recursion Limit: 무한 루프 방어
- 스트리밍 4가지 모드
- Store: Thread를 넘어서는 장기 메모리
- Pregel과 Superstep: 실행 모델의 이해
- Graph API vs Functional API: 선택 기준
- 적용 범위와 한계
LangGraph는 LLM 호출의 추상화(LangChain) 위에 상태 관리와 흐름 제어를 얹는 레이어다.
이 글은 “어떻게 쓰는지”보다 “왜 이 컴포넌트가 필요한지”에 집중한다.
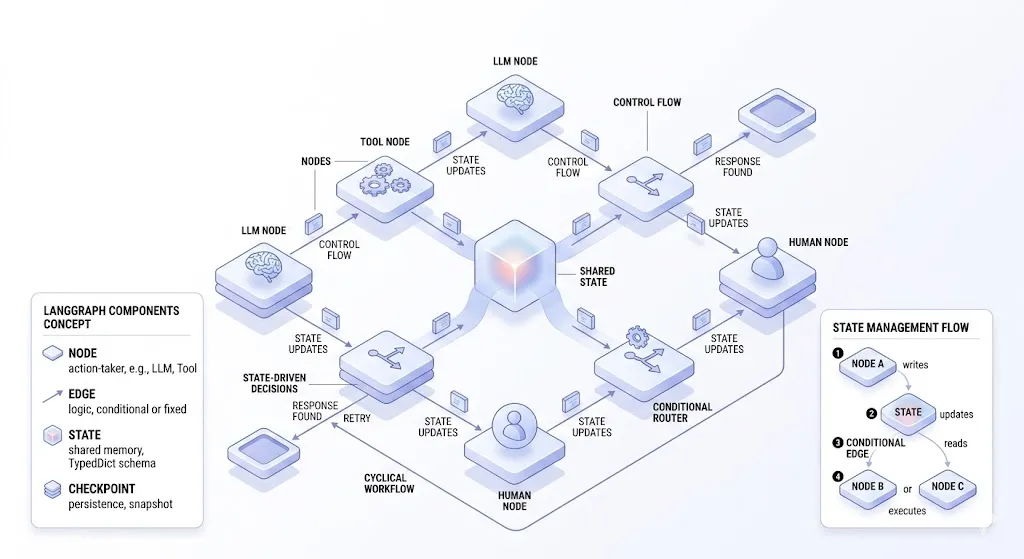
LLM 애플리케이션을 만들 때 가장 먼저 부딪히는 문제는 모델 호출 자체가 아니다. OpenAI API 하나만 쓰는 챗봇이라면 SDK 하나로 충분하다. 문제는 프로덕션으로 가는 길에서 나타난다. 벤더를 바꿀 때마다 호출부를 전부 고쳐야 하고, 도구마다 입출력 형식이 다르고, 대화 히스토리와 세션 상태를 직접 관리해야 하며, 여러 LLM 호출을 조건부로 엮는 로직이 애플리케이션 코드 곳곳에 흩어진다. 이 문제들이 개별적으로는 작지만, 결합되면 사실상 자체 프레임워크를 만드는 것과 다름없다.
LangChain은 이 중 단일 호출의 추상화를 담당하고, LangGraph는 여러 호출의 상태와 흐름 제어를 담당한다. 이 글에서는 LangGraph가 생태계에서 어떤 위치에 있는지 먼저 정리한 뒤, 핵심 컴포넌트 각각이 왜 존재하고 어떻게 동작하는지를 다룬다.
LangChain이 해결하는 문제: LLM 호출의 표준화
LangChain의 핵심 가치는 벤더 추상화다. ChatOpenAI, ChatAnthropic, ChatGoogleGenerativeAI 등 어떤 모델이든 동일한 .invoke() 인터페이스로 호출할 수 있다. 도구 연결은 tool() 함수와 Zod 스키마로 입출력을 표준화하고, 프롬프트 템플릿과 구조화된 출력 파싱도 공통 패턴으로 제공한다. LangSmith와의 연동으로 호출 트레이싱, 비용 추적, 품질 평가까지 관측성이 확보된다.
import { ChatOpenAI } from "@langchain/openai";
import { ChatAnthropic } from "@langchain/anthropic";
// 벤더를 바꿔도 호출 코드가 동일하다
const openai = new ChatOpenAI({ model: "gpt-4o" });
const claude = new ChatAnthropic({ model: "claude-sonnet-4-6-20250514" });
const response = await openai.invoke([
{ role: "user", content: "hello" },
]);이 추상화 덕분에 모델 교체 비용이 거의 사라진다. LiteLLM 같은 AI Gateway가 인프라 수준에서 같은 문제를 해결한다면, LangChain은 애플리케이션 코드 수준에서 해결하는 셈이다.
LangGraph가 해결하는 문제: 상태와 흐름 제어
LangChain이 “이 LLM을 어떻게 호출하지?”에 대한 답이라면, LangGraph는 “이 호출들을 어떤 순서와 조건으로 엮지?”에 대한 답이다. LangChain만으로는 순차 체이닝 이상의 흐름 제어가 불가능하다. 분기, 루프, 병렬 실행, 중단과 재개 같은 제어 흐름이 필요해지는 순간 LangGraph의 영역이 시작된다.
두 레이어의 관계를 정리하면 다음과 같다.
| 관심사 | LangChain | LangGraph |
|---|---|---|
| 단위 | 단일 LLM 호출 | 여러 호출의 조합 |
| 핵심 질문 | ”이 LLM을 어떻게 호출하지?" | "이 호출들을 어떤 순서/조건으로 엮지?” |
| 상태 | 없음 (stateless) | State 스키마 + Checkpointer |
| 흐름 제어 | 순차 체이닝만 | 분기, 루프, 병렬, 중단/재개 |
| 영속화 | 없음 | Checkpointer로 자동 저장/복원 |
한 가지 중요한 점은 LangGraph가 LangChain 없이도 동작한다는 사실이다. @langchain/langgraph만 설치하고 LLM 클라이언트를 직접 사용해도 된다. 다만 LangChain의 모델/도구 추상화와 결합하면 벤더 교체와 도구 표준화가 훨씬 수월해지기 때문에, 실제로는 함께 쓰는 경우가 대부분이다.
대안 프레임워크와의 비교
LangGraph만이 유일한 선택지는 아니다. AI 에이전트 프레임워크는 빠르게 늘어나고 있고, 각각 다른 문제를 우선순위에 둔다.
| 프레임워크 | 특징 | LangGraph 대비 |
|---|---|---|
| Vercel AI SDK | Next.js 친화, 스트리밍 우선, 경량 | 단순한 에이전트에 적합. 복잡한 상태/분기/서브그래프 제어는 약함 |
| Mastra | TypeScript 네이티브, workflow + agent + RAG 통합 | 신생 프레임워크로 생태계가 작지만 성장 중 |
| AutoGen | Microsoft 기반 멀티에이전트 대화 | 대화 기반 협업에 강하지만 그래프 수준 흐름 제어는 제한적 |
| CrewAI | 역할 기반 에이전트 팀 | Python 전용. 선언적이지만 세밀한 상태 제어 부족 |
| 직접 구현 | 프레임워크 의존 없음, 완전한 제어 | 상태 관리, 체크포인팅, 스트리밍을 전부 직접 구현해야 함 |
위 표는 LangGraph의 강점인 상태/흐름 제어 축에 초점을 맞추고 있다. 공정한 비교를 위해 다른 프레임워크가 우위에 있는 축도 함께 봐야 한다.
| 비교 축 | LangGraph 위치 | 대안의 우위 |
|---|---|---|
| 배포 단순성 | 별도 인프라(Checkpointer DB 등) 필요 | Vercel AI SDK는 Vercel에 zero-config 배포, Mastra는 Mastra Cloud 원클릭 배포 제공 |
| 학습 곡선 | Pregel, StateGraph, Reducer 등 고유 개념이 많음 | Vercel AI SDK는 React/Next.js 개발자에게 익숙한 패턴, CrewAI는 선언적 역할 정의만으로 시작 가능 |
| 생태계 크기 | LangChain 생태계에 의존 (강점이자 제약) | Vercel AI SDK는 Next.js/React 생태계 전체와 자연스럽게 통합 |
| 운영 비용 | Checkpointer + Store 인프라 운영 부담 | 경량 프레임워크는 추가 인프라 없이 서버리스로 운영 가능 |
| 팀 적합성 | Python/TypeScript 양쪽 지원이지만 Python 우선 | 프론트엔드 중심 팀이라면 Vercel AI SDK, ML 연구팀이라면 AutoGen이 온보딩이 빠름 |
LangGraph를 선택하는 근거는 그래프 기반 흐름 제어(분기/루프/병렬/서브그래프 선언적 정의), 상태 영속화 내장(Checkpointer + Store), HITL(Human-in-the-Loop) 프레임워크 수준 지원, LangChain 생태계의 도구/벡터 스토어/MCP 어댑터 활용, TypeScript와 Python 양쪽 지원이다.
반대로 약점도 분명하다. 추상화 레이어가 많아 디버깅이 어려울 수 있고(Pregel 실행 모델에 대한 이해가 필요), 단순한 체이닝에는 오버엔지니어링이며, Python 버전이 먼저 업데이트되고 JavaScript가 따라오는 구조라 기능 격차가 존재한다.
멀티에이전트 간 통신 표준까지 고려한다면 A2A Protocol과의 관계도 살펴볼 만하다. LangGraph가 단일 시스템 내 에이전트 흐름을 제어한다면, A2A는 서로 다른 프레임워크로 만든 에이전트들이 표준 프로토콜로 통신하는 문제를 다룬다.
StateGraph: 그래프의 컨테이너
LangGraph의 모든 워크플로우는 StateGraph에서 시작한다. 노드와 엣지를 등록하고, compile()을 호출하면 실행 가능한 그래프 인스턴스가 만들어진다. compile() 전에는 invoke()나 stream()을 호출할 수 없다.
import { StateGraph, START, END } from "@langchain/langgraph";
const graph = new StateGraph(StateAnnotation)
.addNode("classify", classifyNode)
.addNode("respond", respondNode)
.addEdge(START, "classify")
.addEdge("classify", "respond")
.addEdge("respond", END)
.compile();
const result = await graph.invoke({ query: "hello" });START와 END는 각각 그래프의 진입점과 종료점을 나타내는 특수 상수다. START로는 되돌아갈 수 없고, END에 도달하면 실행이 종료된다. 이 구조가 존재하는 이유는 그래프의 경계를 명확히 정의해야 Checkpointer가 실행 상태를 올바르게 저장/복원할 수 있기 때문이다.
Node: 실행의 최소 단위
노드가 존재하는 이유는 그래프의 각 단계를 독립적이고 테스트 가능한 단위로 분리하기 위해서다. 노드는 State를 받아 partial update 객체를 반환하는 함수다. “partial update”라는 점이 핵심인데, 노드는 전체 State를 덮어쓰는 게 아니라 자신이 변경한 필드만 반환한다. LangGraph 런타임이 이 반환값을 기존 State에 병합한다.
const classifyNode = async (
state: typeof StateAnnotation.State
) => {
// state를 직접 변경하면 안 된다 (state.route = "x" 금지)
// 항상 새 객체를 반환한다
return { route: "weather" };
};노드 함수는 세 가지 시그니처를 지원한다. (state) 형태는 단순 노드에서 사용하고, (state, config) 형태는 thread_id나 configurable 값에 접근할 때 사용하며, (state, runtime) 형태는 Store나 stream writer 같은 런타임 컨텍스트가 필요할 때 사용한다.
State를 직접 변경하지 않는 이유는 불변성(immutability) 때문이다. 노드가 State를 직접 수정하면 병렬 실행 시 경쟁 조건이 발생하고, Checkpointer가 변경 전후를 추적할 수 없게 된다. partial update를 반환하는 방식이어야 여러 노드의 결과를 Reducer로 안전하게 병합할 수 있다.
Edge: 노드 간 흐름 정의
에이전트 워크플로우의 본질은 비결정적(non-deterministic)이다. LLM의 응답에 따라 다음 단계가 달라지는 것이 기본 동작이고, 이 분기를 선언적으로 표현하기 위해 엣지가 존재한다. 엣지는 노드 간 실행 순서를 정의한다. 정적 엣지와 조건부 엣지 두 종류가 있다.
정적 엣지는 addEdge("a", "b")로 선언하며, 노드 a가 완료되면 항상 노드 b가 실행된다. 조건부 엣지는 런타임 State를 기반으로 다음 노드를 결정한다.
const routeQuery = async (
state: typeof StateAnnotation.State
) => {
if (state.query.includes("날씨")) return "weather";
return "general";
};
builder.addConditionalEdges(
"classify", // 출발 노드
routeQuery, // 라우팅 함수
["weather", "general"] // 가능한 목적지 (시각화용)
);라우팅 함수의 반환값은 노드 이름과 일치해야 한다. 그래프를 종료하려면 "__end__"를 반환한다. 세 번째 인자(가능한 목적지 배열)는 실행에 영향을 주지 않지만, 그래프 시각화 도구가 엣지를 렌더링하는 데 사용한다.
State 스키마와 Reducer: 데이터의 구조와 병합 규칙
병렬 실행에서 여러 노드가 같은 필드에 쓸 때 값이 어떻게 합쳐지는지 명시적으로 정의하지 않으면 예측 불가능한 결과가 나온다. State 스키마와 Reducer는 이 문제를 해결하기 위해 존재한다. State 스키마는 Annotation.Root()로 정의하며, 그래프 전체에서 공유되는 데이터 구조를 선언한다. 각 필드에는 선택적으로 Reducer를 지정할 수 있다.
import { Annotation } from "@langchain/langgraph";
const StateAnnotation = Annotation.Root({
// reducer 없음: 마지막 write가 덮어씀
query: Annotation<string>,
// reducer 있음: 값이 누적됨
messages: Annotation<string[]>({
reducer: (a, b) => a.concat(b),
default: () => [],
}),
// 정수 합산
count: Annotation<number>({
reducer: (a, b) => a + b,
default: () => 0,
}),
});Reducer는 같은 필드에 여러 노드가 쓸 때 값을 어떻게 합칠지 결정하는 함수다. Reducer가 없으면 마지막 write가 이전 값을 덮어쓴다. 리스트를 누적해야 한다면 concat Reducer를, 숫자를 합산해야 한다면 덧셈 Reducer를 지정한다.
Reducer를 명시적으로 선언하게 만든 설계 결정에는 이유가 있다. 암묵적 병합 규칙(예: “배열은 자동으로 concat”)을 두면 편리해 보이지만, 병렬 실행에서 예측 불가능한 결과가 나올 수 있다. 개발자가 필드별 병합 전략을 명시하면 병렬 노드의 결과가 어떻게 합쳐지는지 코드만 보고 알 수 있다.
가장 흔한 실수는 리스트 필드에 Reducer를 빠뜨리는 것이다. 병렬 노드 3개가 같은 리스트 필드에 결과를 쓰면, Reducer가 없을 경우 마지막 노드의 결과만 남는다.
State에 포함해야 할 것과 제외해야 할 것도 구분이 필요하다. 노드 간 공유 데이터, 라우팅 신호(route: string 같은), 누적 결과는 State에 포함한다. 반면 포매팅된 프롬프트(노드 내부에서 생성), 단일 노드만 사용하는 중간값, 대용량 바이너리(외부 저장소 참조로 대체)는 State에서 제외한다.
병렬 실행: 정적 fan-out과 동적 Send
LangGraph는 두 가지 병렬 실행 방식을 지원한다.
정적 병렬은 컴파일 시점에 병렬 경로가 결정되는 fan-out/fan-in 패턴이다. START에서 여러 노드로 동시에 분기하고, aggregator 노드에서 합류한다.
builder.addEdge(START, "call_llm_1");
builder.addEdge(START, "call_llm_2");
builder.addEdge(START, "call_llm_3");
builder.addEdge("call_llm_1", "aggregator");
builder.addEdge("call_llm_2", "aggregator");
builder.addEdge("call_llm_3", "aggregator");aggregator는 모든 fan-out 노드가 완료된 후에야 실행된다. 합류 지점의 필드에는 반드시 Reducer가 있어야 한다. 없으면 마지막에 완료된 노드의 결과만 남는다.
동적 병렬은 런타임에 병렬 개수가 결정될 때 사용한다. Send 객체를 조건부 엣지 함수에서 반환하면, 각 Send가 독립적인 노드 실행을 트리거한다.
import { Send } from "@langchain/langgraph";
const fanOut = async (
state: typeof StateAnnotation.State
) => {
return state.tasks.map(
(task) => new Send("worker", { task })
);
};
builder.addConditionalEdges(START, fanOut, ["worker"]);
builder.addEdge("worker", "synthesize");Send가 필요한 이유는 map-reduce 패턴 때문이다. “문서 10개를 각각 요약해서 종합”같은 워크플로우에서 문서 수는 런타임에만 알 수 있다. 정적 엣지로는 이를 표현할 수 없고, Send를 통한 동적 분기가 필요하다. 여기서도 수신 필드에 Reducer가 없으면 마지막 worker의 결과만 남는다는 점은 동일하다.
Command: 상태 업데이트와 라우팅의 결합
일반적인 노드는 State 업데이트만 반환하고, 다음 노드로의 라우팅은 엣지가 담당한다. Command는 이 두 가지를 하나의 반환값으로 결합한다.
import { Command } from "@langchain/langgraph";
const decide = async (
state: typeof StateAnnotation.State
) => {
if (state.score > 0.8) {
return new Command({
update: { decision: "pass" },
goto: "approve",
});
}
return new Command({
update: { decision: "fail" },
goto: "reject",
});
};
// Command 목적지를 ends로 명시 (TypeScript 필수)
builder.addNode("decide", decide, {
ends: ["approve", "reject"],
});Command가 별도로 존재하는 이유는 “판단 결과를 State에 기록하면서 동시에 그 결과에 따라 분기”하는 패턴이 매우 흔하기 때문이다. 이걸 노드 반환 + 조건부 엣지로 나누면 State에 라우팅 신호를 저장하고 별도의 라우팅 함수가 그 신호를 읽는 간접 참조가 생긴다. Command는 이 간접 참조를 제거한다.
주의할 점은 TypeScript에서 addNode에 { ends: [...] } 옵션으로 Command의 가능한 목적지를 명시해야 한다는 것이다. 또한 정적 addEdge("decide", "approve")가 동시에 있으면 Command의 라우팅과 정적 엣지가 모두 실행되므로 충돌에 주의해야 한다.
서브그래프에서 부모 그래프의 노드로 라우팅할 때는 graph: Command.PARENT를 지정한다.
return new Command({
update: { result: data },
graph: Command.PARENT,
goto: "next",
});Checkpointer: 상태 영속화의 기반
매 단계의 State 스냅샷을 저장하고, thread별로 격리하고, 과거 지점에서 재실행하는 로직을 애플리케이션마다 직접 구현하면 그 자체가 하나의 프레임워크가 된다. Checkpointer는 이 반복 비용을 프레임워크 수준에서 해결하기 위해 존재한다. Checkpointer는 그래프 실행 상태를 매 superstep마다 자동 저장한다. 중단/재개, 시간 여행, 에러 복구의 기반이 된다.
// 개발 환경: 메모리 저장 (재시작 시 소멸)
import { MemorySaver } from "@langchain/langgraph";
const graph = builder.compile({
checkpointer: new MemorySaver(),
});
// 프로덕션: PostgreSQL 영속 저장
import { PostgresSaver } from
"@langchain/langgraph-checkpoint-postgres";
const checkpointer =
PostgresSaver.fromConnString("postgresql://...");
const graph = builder.compile({ checkpointer });Checkpointer 없이도 그래프는 실행되지만, Thread, interrupt, Time Travel 같은 기능은 전부 Checkpointer가 전제 조건이다.
Thread와 Time Travel: 세션 격리와 상태 탐색
Thread는 thread_id로 격리되는 실행 세션이다. 같은 그래프를 여러 사용자나 대화가 독립적으로 사용할 수 있다.
const config = {
configurable: { thread_id: "user-123-session-1" },
};
const result = await graph.invoke(
{ query: "hello" }, config
);thread_id가 다르면 State가 완전히 격리된다. 같은 thread_id로 다시 invoke하면 이전 State 위에서 이어진다. Checkpointer 없이는 Thread 기능이 동작하지 않는다.
Time Travel은 Checkpointer가 저장한 히스토리를 활용하여 과거 시점의 State를 조회하거나, 과거 지점에서 다시 실행하는 기능이다.
// 히스토리 조회
const states = [];
for await (const state of graph.getStateHistory(config)) {
states.push(state);
}
// 과거 지점에서 재실행
const result = await graph.invoke(null, states[2].config);
// Fork: 과거 상태를 수정한 뒤 분기 실행
const fork = await graph.updateState(
past.config, { messages: ["edited"] }
);
const forked = await graph.invoke(null, fork);Time Travel이 유용한 이유는 LLM 기반 워크플로우의 디버깅이 본질적으로 어렵기 때문이다. 같은 입력을 줘도 LLM 응답이 달라지고, 중간 단계에서 잘못된 판단이 이후 전체 흐름에 영향을 준다. 특정 시점의 State로 돌아가서 다시 실행하거나, 값을 수정한 뒤 분기 실행할 수 있으면 원인 추적이 훨씬 수월해진다.
interrupt와 Human-in-the-Loop: 실행 중단과 재개
interrupt()는 그래프 실행을 일시 중지하고, 외부 입력을 받은 뒤 Command({ resume: ... })로 재개하는 메커니즘이다. 세 가지 전제조건이 있다: Checkpointer, thread_id, JSON-serializable한 payload.
import { interrupt, Command } from "@langchain/langgraph";
function reviewNode(
state: typeof StateAnnotation.State
) {
const decision = interrupt({
draft: state.draft,
action: "Please review",
});
return { approved: decision };
}실행 측에서는 첫 번째 stream()이 interrupt에서 멈추고, 사용자 판단 후 Command({ resume: true })를 전달하면 중단 지점부터 재개된다.
const config = {
configurable: { thread_id: "review-1" },
};
// 1차 실행: interrupt에서 멈춤
for await (const chunk of await graph.stream(
{ draft: "Initial draft" }, config
)) { /* ... */ }
// 재개: resume 값을 전달
for await (const chunk of await graph.stream(
new Command({ resume: true }), config
)) { /* ... */ }멱등성 규칙이 하나 있다. interrupt() 이전 코드는 resume할 때마다 재실행된다. 따라서 DB 쓰기 같은 부수효과는 반드시 interrupt 이후에 배치해야 한다. 이 규칙을 모르면 resume할 때마다 같은 API를 중복 호출하는 버그가 생긴다.
Recursion Limit: 무한 루프 방어
루프가 있는 그래프에서 LLM이 종료 조건을 만족하지 못하면 무한 루프에 빠질 수 있다. recursionLimit은 superstep 수를 제한하여 이를 방어한다. 기본값은 25다.
const result = await graph.invoke(input, {
recursionLimit: 50,
});초과 시 GraphRecursionError가 발생한다. 루프가 있는 그래프에서는 END로 가는 조건부 경로와 함께 이중 안전장치로 사용하는 것이 권장된다. 조건부 경로가 “논리적 종료 조건”이라면, recursionLimit은 “물리적 종료 조건”이다.
스트리밍 4가지 모드
LangGraph는 네 가지 스트리밍 모드를 제공한다.
| 모드 | 내용 | 용도 |
|---|---|---|
values | 매 step 후 전체 State | 상태 모니터링 |
updates | 노드별 State delta (기본값) | 증분 추적 |
messages | LLM 토큰 + 메타데이터 | 채팅 UI |
custom | 사용자 정의 데이터 | 진행률 표시 |
values는 디버깅이나 전체 상태를 추적할 때, updates는 어떤 노드가 어떤 변경을 가했는지 추적할 때, messages는 채팅 UI에서 토큰 단위 스트리밍이 필요할 때, custom은 노드 내부에서 진행률 같은 임의 데이터를 전달할 때 사용한다.
// values 모드: 매 step의 전체 State
for await (const chunk of await graph.stream(
input, { streamMode: "values" }
)) {
console.log(chunk.messages.at(-1)?.content);
}
// 복수 모드 동시 사용
for await (const [mode, chunk] of await graph.stream(
input, { streamMode: ["updates", "custom"] }
)) {
if (mode === "custom") console.log(chunk);
}노드 내부에서 커스텀 데이터를 스트리밍하려면 config.writer를 사용한다. 이 방식으로 “현재 3/10 문서 처리 중”같은 진행률을 프론트엔드에 실시간으로 전달할 수 있다.
Store: Thread를 넘어서는 장기 메모리
Checkpointer의 데이터는 thread에 묶여 있어 thread가 끝나면 의미가 사라진다. 사용자 선호도처럼 thread와 무관하게 영속해야 하는 데이터를 위해 Store가 별도로 존재한다. Checkpointer가 thread 단위의 단기 기억이라면, Store는 thread를 넘어 영속하는 장기 기억이다. 사용자 선호도, 학습된 패턴 같은 정보를 thread와 무관하게 저장하고 검색할 수 있다.
import { InMemoryStore } from "@langchain/langgraph";
const store = new InMemoryStore();
const graph = builder.compile({ checkpointer, store });노드 안에서 Store에 접근하여 의미 검색(semantic search)으로 관련 기억을 찾거나, 새로운 기억을 저장한다.
const respond = async (state, runtime) => {
// 의미 검색으로 관련 기억 조회
const memories = await runtime.store?.search(
[state.userId, "preferences"],
{ query: state.messages.at(-1)?.content, limit: 3 }
);
// 새 기억 저장
await runtime.store?.put(
[state.userId, "preferences"],
crypto.randomUUID(),
{ preference: "concise responses" }
);
return { response: "..." };
};Pregel과 Superstep: 실행 모델의 이해
LangGraph는 Google Pregel 논문에 기반한 message-passing 모델로 실행된다. 이 실행 모델을 이해하면 디버깅 시 노드 실행 순서를 예측할 수 있다.
핵심 개념은 superstep이다. 병렬 실행 가능한 노드들은 같은 superstep에서 동시에 실행되고, 순차적으로 실행해야 하는 노드들은 별도의 superstep으로 분리된다. 각 superstep이 완료되면 State가 Checkpointer에 저장된다.
Superstep 0: [START] -> node_a
Superstep 1: node_a -> [node_b, node_c] (병렬)
Superstep 2: [node_b, node_c] -> aggregator
Superstep 3: aggregator -> [END]한 superstep 내에서 하나의 branch가 실패하면 해당 superstep 전체가 rollback된다(transactional). recursionLimit이 제한하는 것도 바로 이 superstep 수다. streamMode: "debug"를 사용하면 superstep 단위 실행 과정을 관찰할 수 있다.
지금까지 설명한 StateGraph, Node, Edge, Reducer, Checkpointer는 모두 Pregel 위에서 동작하는 Graph API의 구성요소다. LangGraph는 이 Graph API 외에 더 단순한 진입점인 Functional API도 제공한다.
Graph API vs Functional API: 선택 기준
LangGraph는 Graph API(StateGraph)와 Functional API(task/entrypoint) 두 가지를 제공한다.
| 기준 | Graph API (StateGraph) | Functional API (task/entrypoint) |
|---|---|---|
| 적합한 경우 | 복잡한 분기/루프/병렬 | 선형 파이프라인, 간단한 워크플로우 |
| 시각화 | 그래프 다이어그램 자동 생성 | 제한적 |
| 상태 관리 | State 스키마 + Reducer 명시적 | getPreviousState() + entrypoint.final() |
| HITL | interrupt 위치를 노드 단위로 제어 | entrypoint 내부에서 interrupt |
| 학습 곡선 | 높음 | 낮음 |
import { task, entrypoint } from "@langchain/langgraph";
// Functional API: 선형 파이프라인에 적합
const process = task("process", async (data: string) => {
return data.toUpperCase();
});
const pipeline = entrypoint(
{ name: "pipeline", checkpointer },
async (input: string) => {
const result = await process(input);
return result;
}
);복잡한 멀티에이전트 시스템에서는 Graph API, 단순 도구 체인이나 프로토타이핑에서는 Functional API가 적합하다. 프로젝트 내에서 혼용도 가능하다. 중요한 것은 “그래프 시각화와 노드 단위 제어가 필요한가?”라는 질문이다. 답이 “예”라면 Graph API, “아니오”라면 Functional API로 시작하되 필요할 때 Graph API로 전환하면 된다.
적용 범위와 한계
LangGraph가 적합한 경우는 분명하다. 여러 LLM 호출을 조건부로 엮어야 하고, 실행 상태를 영속화해야 하며, 사용자 승인 같은 중단/재개가 필요하고, 병렬 실행이나 서브그래프 분리가 요구되는 시스템이다. 전형적으로는 멀티스텝 에이전트, 문서 처리 파이프라인, 승인 워크플로우가 여기에 해당한다.
반면 과도한 선택이 되는 경우도 있다. 단일 LLM 호출로 끝나는 챗봇, 단순한 RAG 파이프라인(검색 -> 생성), 도구 하나를 호출하는 간단한 에이전트라면 LangChain만으로 충분하거나 Vercel AI SDK 같은 경량 프레임워크가 더 적절하다. LangGraph의 추상화 레이어(StateGraph, Reducer, Checkpointer, Pregel)는 복잡한 문제를 해결하기 위해 존재하며, 그 복잡함이 없는 곳에 도입하면 학습 비용만 늘어난다.
구체적인 실패 패턴도 알아두어야 한다. 첫째, Reducer 누락에 의한 데이터 소실이다. 병렬 노드 3개가 같은 리스트 필드에 결과를 쓸 때 Reducer를 지정하지 않으면, 마지막에 완료된 노드의 결과만 남고 나머지 두 노드의 결과는 사라진다. 병렬 실행의 완료 순서는 비결정적이므로 실행할 때마다 결과가 달라지는 버그로 나타나 원인 추적이 어렵다. 둘째, Graph 구조 변경 시 Checkpointer 마이그레이션 비용이다. 프로덕션에서 운영 중인 그래프의 노드를 추가/삭제하거나 State 스키마 필드를 변경하면, 기존 checkpoint에 저장된 State 구조와 달라진다. 진행 중인 thread를 resume하면 스키마 불일치로 에러가 발생하고, 이를 안전하게 마이그레이션하려면 별도의 호환 레이어나 기존 thread 종료 전략이 필요하다.
도입 여부를 단일 질문으로 판단하는 것은 위험하다. 다음 체크리스트를 복수 축으로 검토해야 한다.
- 상태 영속화 필요성: 실행 중간에 상태를 저장하고 나중에 이어서 실행해야 하는가? LangGraph의 가장 강한 영역이다.
- 팀의 장기 유지보수 역량: Pregel 실행 모델, StateGraph, Reducer 등 LangGraph 고유 개념을 팀이 장기적으로 이해하고 유지보수할 수 있는가? 핵심 담당자 이탈 시 블랙박스가 되는 리스크는 없는가?
- 규제/보안 제약: 외부 프레임워크 의존성에 대한 보안 심사, 라이선스 검토, 데이터 처리 규정(Checkpointer에 저장되는 State에 민감 정보가 포함되는지)을 통과할 수 있는가?
- 복잡성 대비 이득: LangGraph가 제공하는 상태 관리, HITL, 스트리밍 등의 이점이 추상화 레이어 추가에 따른 디버깅 난이도 상승과 인프라 운영 비용을 상회하는가?
- 대안 프레임워크 적합성: 위 축을 검토한 결과 LangGraph의 핵심 기능(상태 영속화, 복잡한 분기/루프)이 필요하지 않다면, 팀 스택에 맞는 경량 프레임워크가 더 적절한 선택이다.
다음 편에서는 이 컴포넌트들을 조합하여 실제 시스템을 설계하는 패턴과 프로덕션 고려사항을 다룬다. 2편: LangGraph 설계 패턴과 프로덕션 전략에서 계속된다.