Cloudflare 위에 블로그 전부 올리기 — Pages, Workers, AE, KV, D1 통합 아키텍처
목차
- Before & After
- CF Pages 전환 — 예상 못한 부산물이 더 컸다
- 왜 옮겼나
- 잃은 것
- 얻은 것 — 대역폭 무제한, 그리고 RUM
- GoatCounter를 버린 이유
- D1 도입 — 퀴즈가 관계형 데이터를 요구했다
- Workers 3종 — 하나였던 게 셋이 된 이유
- blog-api — 가장 크고, 가장 복잡한 놈
- quiz-api — D1 전담
- deploy-notify — 가장 작고, 가장 먼저 만든 놈
- 데이터 저장소 — 왜 3종을 쓰는가
- 시리즈 기능 — 콘텐츠가 쌓이면 구조가 필요하다
- 비용 — 현재 트래픽에서 0원
- 정리 — 덜어내는 방향으로 옮겨왔다
GitHub Pages에서 출발한 정적 블로그가 Cloudflare 생태계 위에서 완전한 서버리스 플랫폼이 되기까지의 결정과정에 대한 마지막 내용이다.

이 글은 블로그 제작기 시리즈의 마지막 편이다. 1편에서 정적 사이트에 댓글·좋아요·분석 기능을 서버 없이 붙이는 방법을 찾았고, 2편에서 하루 만에 12종 기능을 쌓으며 “기능은 되는데 정리가 안 된” 상태를 만들었고, 3편에서 분석 도구를 갈아엎다가 vibe coding의 실체를 경험했다.
이 글에서는 3편 이후 일어난 변화들 — CF Pages 전환, GoatCounter 폐기, D1 도입, Workers 분화 — 의 전후 맥락과 의사결정을 정리한다.
Before & After
먼저 전체 그림부터 보자. 위가 3편 시점, 아래가 지금이다.
AS-IS (3편 시점)
graph LR
GH[GitHub Pages] --> CF1[Cloudflare<br/>DNS Proxy]
CF1 --> W1[Worker 1개<br/>좋아요·조회수]
W1 --> KV1[KV<br/>조회수 직접 계산]
GC[GoatCounter] -.->|외부 SaaS| GHTO-BE (현재)
flowchart TB
CP[CF Pages<br/>빌드·배포·CDN] --> RUM[RUM<br/>조회수 자동 수집]
CP --> WB[Worker: blog-api<br/>대시보드·좋아요]
CP --> WQ[Worker: quiz-api<br/>문제은행·채점]
CP --> WN[Worker: deploy-notify<br/>Telegram 알림]
WB --> KV2[KV<br/>baseline·좋아요·스냅샷]
WB --> AE[Analytics Engine<br/>체류·스크롤]
WQ --> D1[D1<br/>퀴즈·답변]변화의 핵심은 세 가지다. CF Pages 전환으로 RUM을 얻고 GoatCounter를 버린 것, D1 도입으로 퀴즈 시스템이 가능해진 것, 그리고 Workers가 역할별로 분화한 것.
CF Pages 전환 — 예상 못한 부산물이 더 컸다
왜 옮겼나
GitHub Pages 자체에 불만이 있었던 건 아니다. 문제는 Cloudflare Workers와 같은 도메인에서 공존하기 어려웠던 것이다.
GitHub Pages는 blog.neocode24.com을 CNAME으로 서빙하고, Workers는 같은 도메인의 /api/* Route를 처리한다. 이 조합이 DNS Proxy 설정에서 미묘하게 충돌했다. 간헐적으로 Workers Route가 안 먹히거나, Pages 캐시 퍼지 타이밍이 어긋나는 일이 생겼다. 근본 원인은 GitHub Pages와 Cloudflare Workers가 서로 다른 인프라 위에서 같은 도메인을 나눠 쓰는 구조 자체에 있었다.
CF Pages로 옮기면 Pages와 Workers가 같은 Cloudflare 인프라에서 동작한다. Route 충돌이 원천적으로 사라진다.
잃은 것
솔직히 거의 없다. 빌드 500회/월 제한이 유일한 차이인데, 현재 월 ~30회 빌드라 한참 여유가 있다. GitHub Actions의 커스텀 빌드 파이프라인(테스트·린트 등)을 쓰고 있었다면 이전이 더 복잡했겠지만, 이 블로그는 npm run build 한 줄이 전부라 전환 비용이 없었다.
얻은 것 — 대역폭 무제한, 그리고 RUM
대역폭 무제한은 기대한 이점이었다. GitHub Pages는 월 100GB 소프트 리밋이 있어서, 이미지가 많은 블로그가 바이럴 타면 걸릴 수 있다. CF Pages는 대역폭 제한이 없다.
RUM(Real User Monitoring)은 예상 못한 부산물이었다. CF Pages를 쓰면 같은 계정의 Web Analytics가 자동으로 붙는다. JavaScript beacon이 페이지 로드마다 발사되고, 페이지뷰·방문자·Core Web Vitals를 수집한다. GraphQL API로 쿼리할 수 있다.
이 RUM 데이터가 GoatCounter의 역할을 거의 대체했다.
GoatCounter를 버린 이유
GoatCounter는 좋은 서비스다. 프라이버시 친화적이고, 무료 셀프호스팅도 가능하다. 하지만 두 가지 문제가 있었다.
첫째, 외부 의존성. GoatCounter SaaS가 죽으면 조회수가 안 보인다. 실제로 간헐적 다운타임을 몇 번 겪었다.
둘째, KV 조회수 계산 로직의 복잡도. GoatCounter 시절에는 조회수를 KV에서 직접 카운팅했다 — 페이지 로드마다 Worker가 KV를 읽고 +1 하고 다시 쓰는 구조. 이게 KV의 eventual consistency와 만나면 동시 요청에서 카운트가 씹히는 문제가 생긴다. rate limiting, dedup 로직까지 Worker에 직접 구현해야 했다.
RUM이 있으면 이 복잡도가 사라진다. 조회수는 RUM이 자동으로 세고, Worker는 그걸 읽기만 하면 된다. KV에는 GoatCounter → RUM 전환 시점의 누적 조회수(baseline)만 고정값으로 남기고, 이후 조회수는 RUM GraphQL에서 가져온다.
총 조회수 = KV baseline(고정) + RUM(전환일~오늘)RUM 전환 이후 만들어진 대시보드의 모습이다. GoatCounter 시절에는 불가능했던 체류시간 분포, 완독률, D1/KV 사용량까지 한 화면에서 볼 수 있게 됐다.
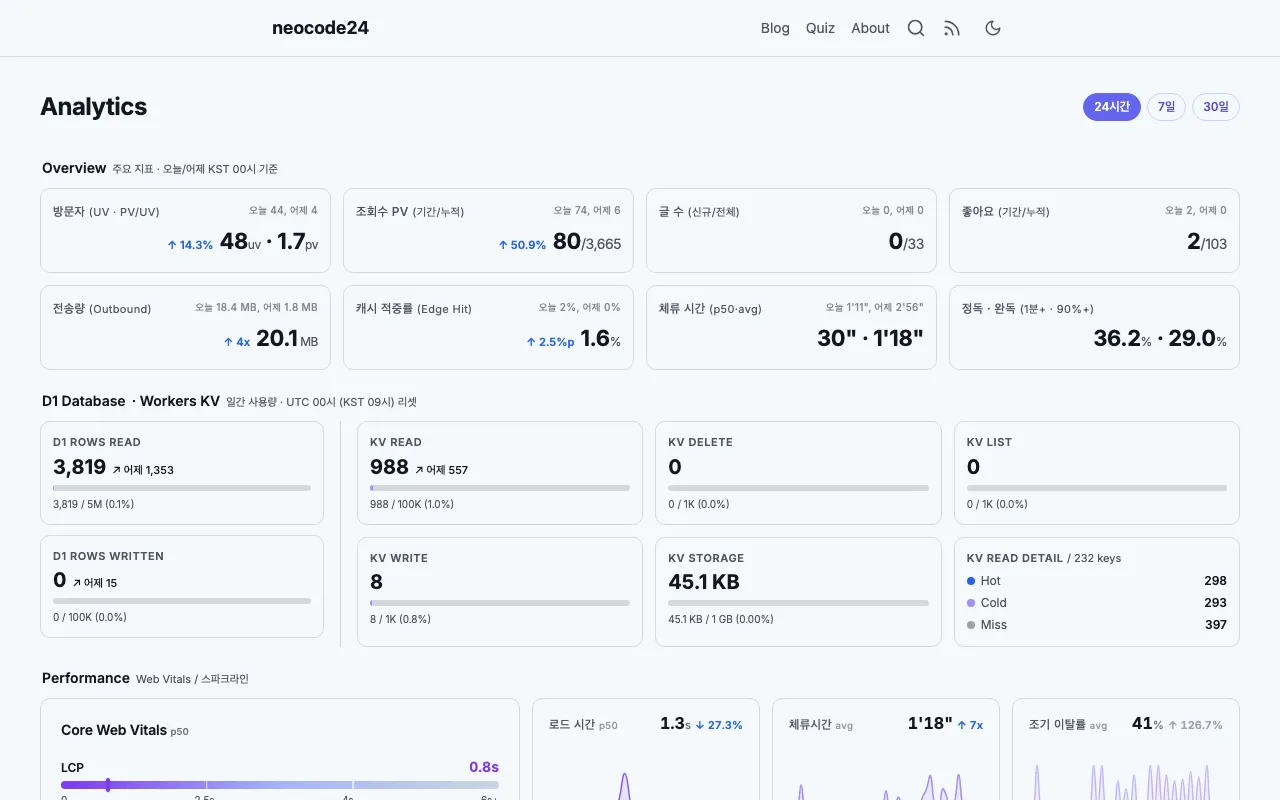
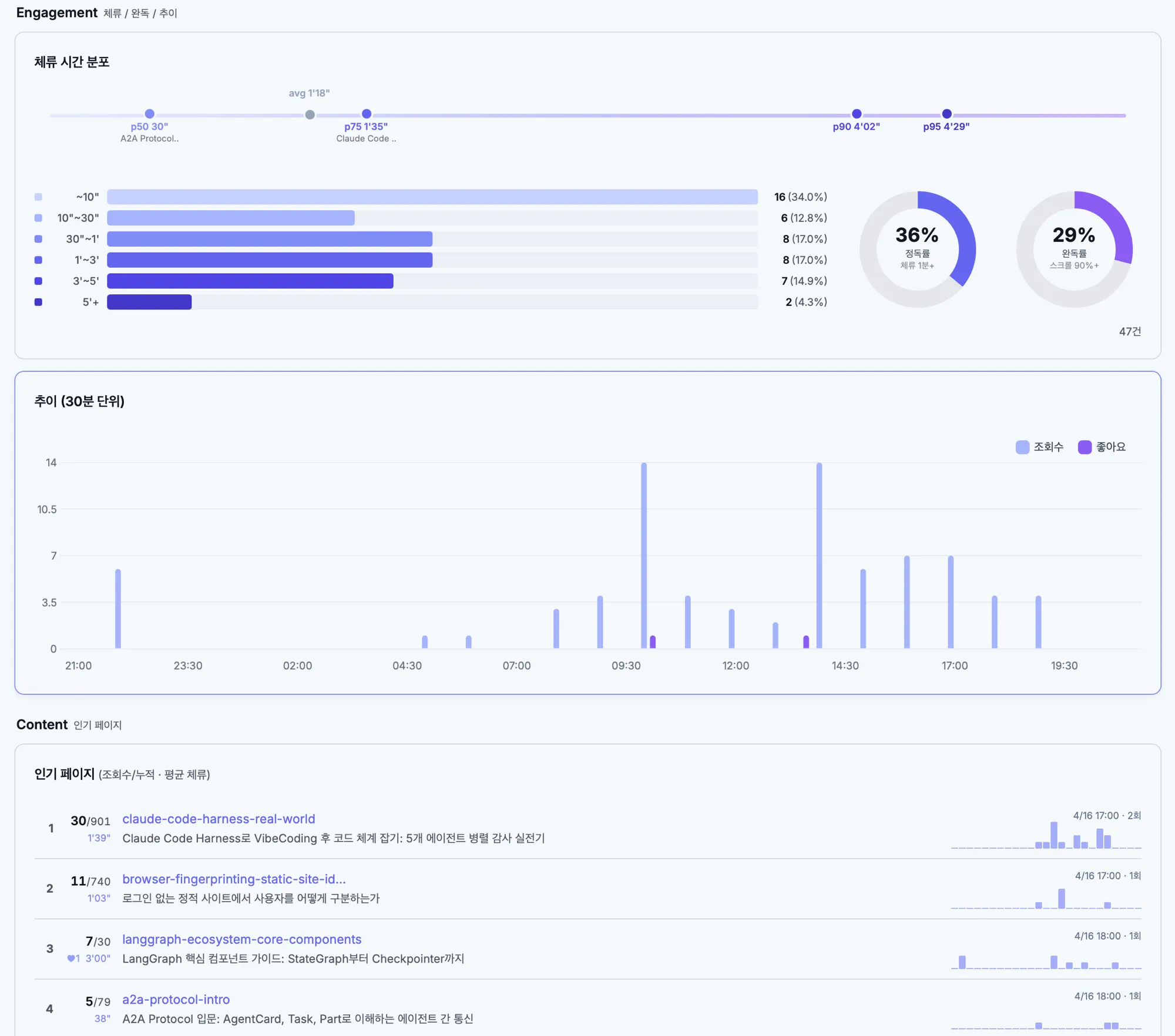
이 구조가 완벽하진 않다. 광고 차단기가 RUM beacon을 막으면 10~15% 정도 undercount된다. 하지만 “정확한 숫자”보다 “추세 파악”이 목적이라면 충분하고, Worker의 KV 읽기-쓰기-dedup 로직이 통째로 사라진 단순화가 훨씬 값졌다.
D1 도입 — 퀴즈가 관계형 데이터를 요구했다
블로그에 간격 반복 퀴즈 시스템을 붙이면서 새로운 데이터 저장소가 필요해졌다. 퀴즈 문제은행(question, options, answer, difficulty, tags)과 답변 이력(quiz_id, user_answer, correct, answered_at)은 명백한 관계형 데이터다.
KV에 넣을 수 있었을까? 기술적으로는 가능하다. quiz:{id} 키에 JSON을 넣고, 태그별 조회는 별도 인덱스 키를 관리하면 된다. 하지만 “난이도 medium인 langgraph 태그 문제 중 아직 안 풀은 것”을 KV로 쿼리하려면 인덱스 키가 기하급수적으로 늘어난다. SQL 한 줄이면 끝나는 걸 KV 인덱싱으로 시뮬레이션하는 건 명백히 잘못된 선택이다.
AE(Analytics Engine)도 후보였지만, AE는 쓰기 전용이다. 개별 레코드를 조회하거나 수정할 수 없다. 퀴즈 답변 통계는 AE에 쌓지만, 문제은행 자체는 CRUD가 필요하다.
D1 위에서 동작하는 퀴즈 페이지의 현재 모습이다. 난이도별 문제 분포, 기간별 정답률 추이, 실제 문제 출제까지 모두 D1 + AE 조합으로 서빙된다.
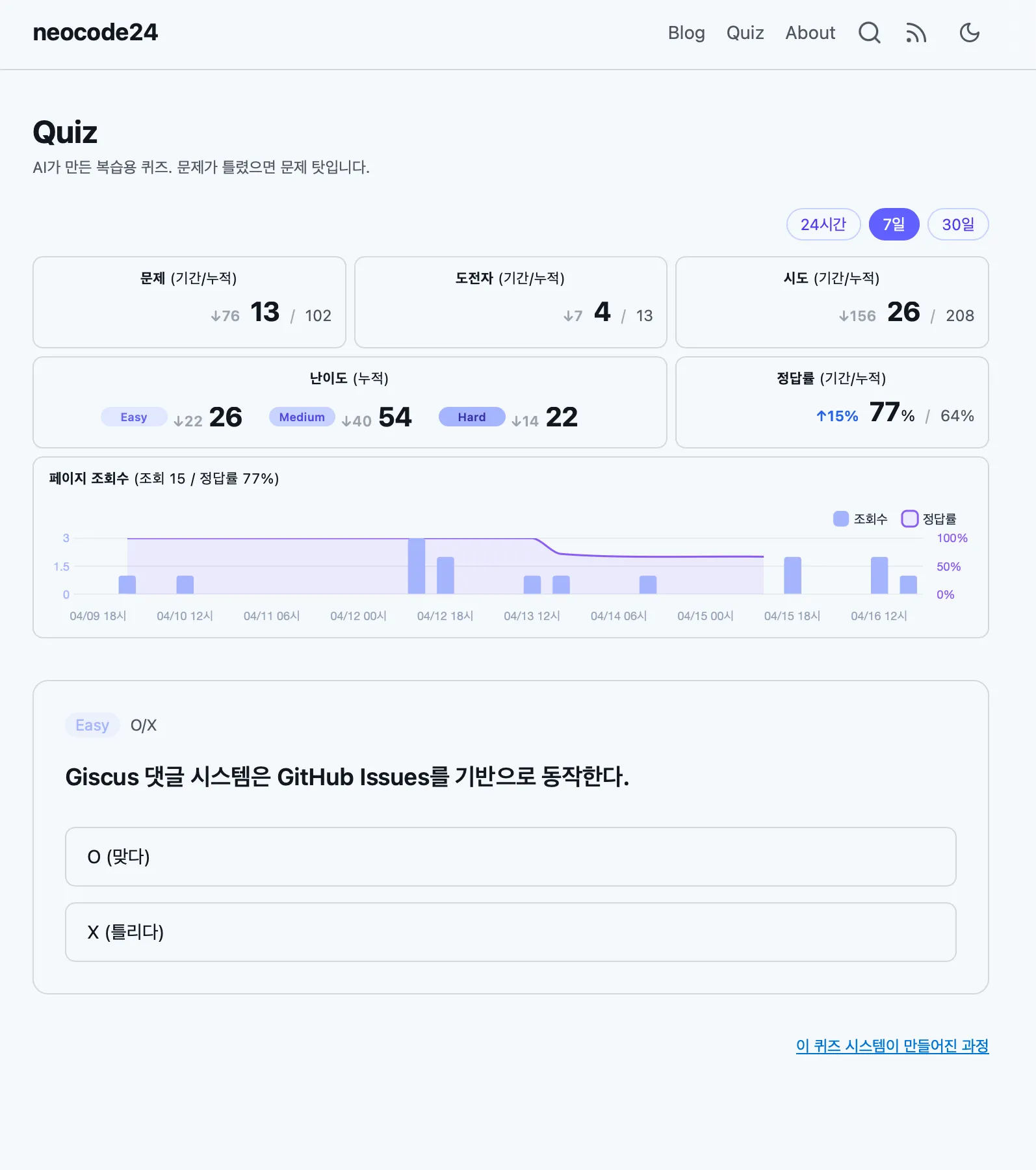
D1은 Cloudflare의 SQLite 서비스다. Workers에서 바로 쿼리할 수 있고, 무료 플랜에서 읽기 500만/일, 쓰기 10만/일을 제공한다. 퀴즈 규모에서는 한참 남는다. D1은 글로벌 리드 레플리카를 지원하므로 읽기 지연은 크지 않고, 쓰기는 프라이머리 리전을 경유한다. 퀴즈 답변 제출(쓰기) 빈도가 낮아서 체감되는 수준은 아니다.
Workers 3종 — 하나였던 게 셋이 된 이유
처음에는 Worker가 하나였다. 좋아요 토글하고, 조회수 세는 게 전부였으니까. 그런데 대시보드가 생기고, 체류시간 수집이 붙고, 퀴즈 API가 필요해지면서 하나의 Worker가 감당하기 어려워졌다.
분리한 기준은 “배포 단위”다. 좋아요 로직을 고칠 때 퀴즈 API까지 같이 배포되는 건 불필요한 리스크다. 역할이 명확히 다른 기능은 Worker를 나누는 게 맞다.
blog-api — 가장 크고, 가장 복잡한 놈
좋아요·조회수·체류시간·스크롤 깊이 수집, 그리고 이 모든 데이터를 합쳐서 대시보드로 내보내는 역할. 3편 시점에는 AE가 조회수·좋아요 이벤트까지 담당했지만, RUM 전환 이후 조회수는 RUM으로 넘어가면서 AE는 체류시간·스크롤 깊이 같은 커스텀 인게이지먼트 전담으로 역할이 줄었다. 4개 데이터 소스(RUM GraphQL, AE SQL, KV, Zone HTTP)를 병렬로 묶어서 한 번에 응답한다.
매일 KST 자정에 Cron으로 전일 스냅샷을 KV에 저장한다. “어제 대비 변화량”을 계산하려면 과거 시점의 고정된 숫자가 필요한데, RUM은 실시간 집계라서 과거 값이 미세하게 흔들릴 수 있기 때문이다.
quiz-api — D1 전담
문제 적재, 랜덤 출제, 채점, 통계. 내부 엔드포인트(/api/quiz/bank, /api/quiz/due)는 Secret 헤더로 인증하고, 공개 엔드포인트(/api/quiz/random, /api/quiz/answer)는 블로그에서 누구나 사용 가능하다.
deploy-notify — 가장 작고, 가장 먼저 만든 놈
CF Pages 배포 웹훅 → Telegram 알림. 이게 사실 Workers를 처음 써본 계기다. “배포되면 알림 오게 하고 싶다”는 단순한 욕구에서 시작해서, Worker라는 도구에 익숙해졌고, 이후 blog-api와 quiz-api로 확장된 것이다.
데이터 저장소 — 왜 3종을 쓰는가
저장소가 3개(KV, AE, D1)인 건 의도적 설계라기보다 각 기능이 요구하는 데이터 특성이 달랐기 때문이다.
| 데이터 | 특성 | 저장소 | 왜 |
|---|---|---|---|
| 좋아요 카운터 | 단순 증감, 빠른 읽기 | KV | 집계 불필요, 키 하나로 끝남 |
| baseline 조회수 | 한 번 쓰고 계속 읽기 | KV | 고정값, 변경 없음 |
| 체류시간·스크롤 | append-only 시계열 | AE | 집계 쿼리 필수, 개별 조회 불필요 |
| 퀴즈 문제·답변 | CRUD + JOIN | D1 | 관계형 쿼리, 태그·난이도 필터링 |
하나로 통일하면 안 되나? D1 하나에 전부 넣을 수도 있다. 하지만 체류시간 데이터를 매 페이지 로드마다 D1에 INSERT하면 쓰기 한도(10만/일)를 빠르게 먹고, 집계 성능도 AE의 네이티브 시계열 쿼리와는 비교가 안 된다. KV의 좋아요 카운터를 D1로 옮기면 단순한 +1 연산에 SQL 커넥션 오버헤드가 붙는다.
운영 복잡도는 진짜 대가다. 모니터링 포인트 3개, 쿼리 방식 3종(GraphQL, SQL API, KV get), 장애 원인 추적도 더 어렵다. 현재 트래픽(일 PV 수백)에서는 각 저장소의 무료 한도를 1% 미만으로 쓰고 있어 부담이 없지만, 규모가 커지면 “이걸 하나로 합쳐야 하나”라는 질문이 돌아올 수 있다.
시리즈 기능 — 콘텐츠가 쌓이면 구조가 필요하다
글이 30편을 넘기면서 “관련 글끼리 묶어서 보여주고 싶다”는 필요가 생겼다. 태그로는 부족했다 — 태그는 주제 분류일 뿐, 순서가 있는 학습 흐름을 표현할 수 없다. LangGraph 시리즈는 1편을 먼저 읽어야 2편이 이해되는 구조인데, 태그 페이지에서는 그냥 날짜순으로 나열될 뿐이다.
포스트 내부에는 시리즈 네비게이션이, 별도 페이지에는 시리즈 목록이 생겼다.

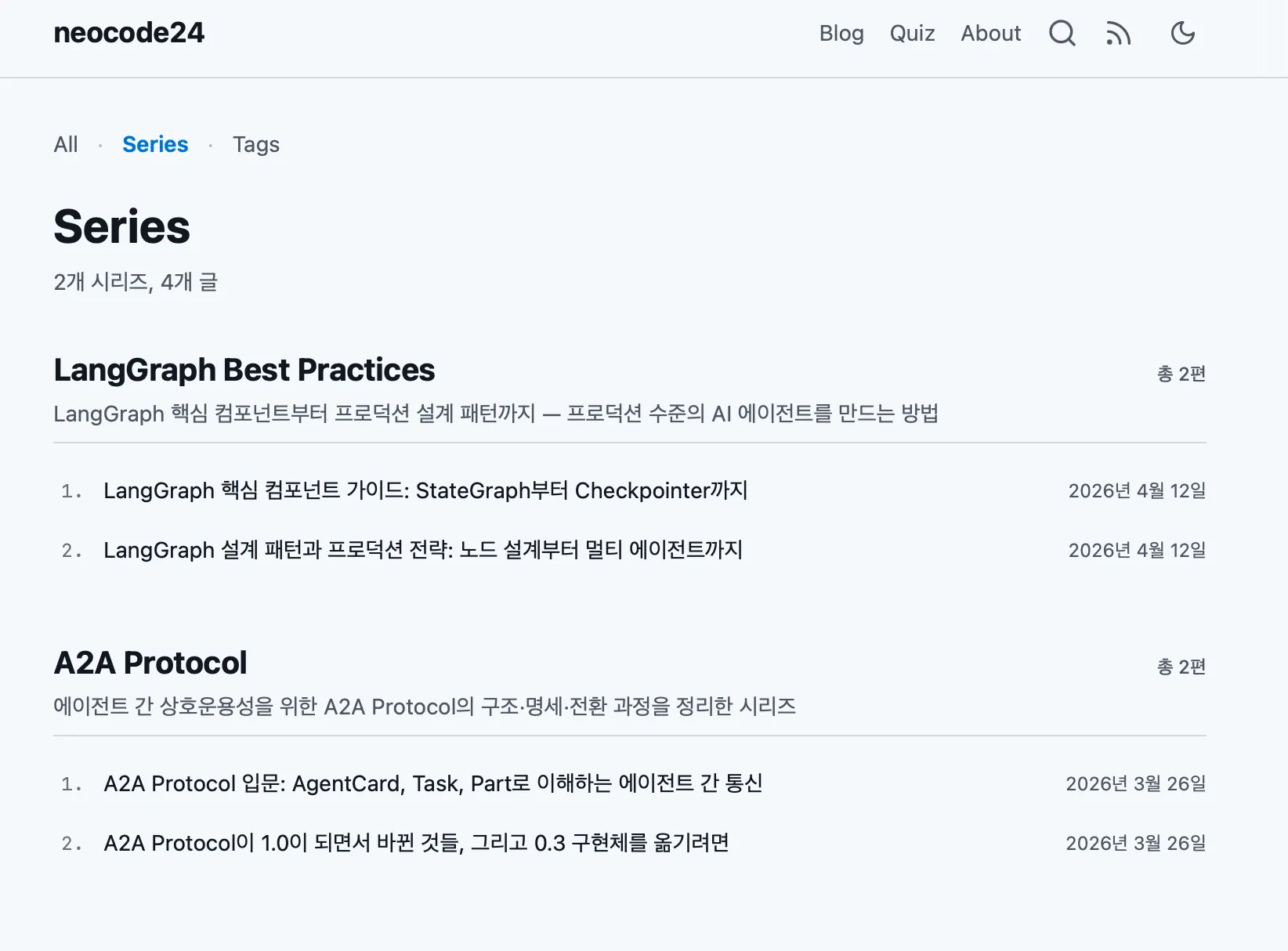
시리즈 메타를 중앙에서 관리하고 각 포스트가 참조하는 구조를 만들었다. 시리즈별로 수동 순서(학습형)와 발행일 순서(시간형)를 선택할 수 있고, 시리즈 목차 페이지가 자동 생성된다. 시리즈 도입 과정에서 대시보드 조회수 집계가 오염되는 사이드 이펙트가 발견돼서, Worker의 slug 추출 로직도 함께 보강했다.
그리고 이 글이 바로 그 시리즈의 마지막 편이다.
비용 — 현재 트래픽에서 0원
“서버 비용 0원”은 이 블로그의 현재 규모(일 PV 수백, API ~1,000요청/일)에서 성립하는 사실이다. 보편적 진실이 아니다.
| 리소스 | 무료 한도 | 현재 사용량 | 초과 시 |
|---|---|---|---|
| Pages | 빌드 500회/월 | ~30회/월 | Paid 무제한 |
| Workers | 10만 요청/일 | ~1,000/일 | Paid $5/월 |
| KV | 읽기 10만/일 | 한도의 ~1% | Paid에 포함 |
| AE | 10만 이벤트/일 | ~500/일 | 종량 과금 |
| D1 | 읽기 500만/일 | ~100/일 | 종량 과금 |
| RUM | 무제한 | — | 무료 |
월 PV 30만 이하면 현실적으로 $0. 그 이상이면 Workers Paid($5/월) + 종량제로 $5~$10/월 수준이 된다. GitHub Pages 시절에도 GoatCounter SaaS 유료 플랜을 쓰면 비슷한 비용이었으니, 총 비용이 크게 달라지진 않는다. 달라진 건 외부 서비스 의존이 줄고, 한 플랫폼 안에서 관리할 수 있게 된 것이다.
정리 — 덜어내는 방향으로 옮겨왔다
되돌아보면 각 전환의 공통점이 있다. “더 나은 기술”이 아니라 “하나를 덜어내려고” 옮긴 것이다.
- CF Pages 전환 → GoatCounter를 덜어냄
- RUM 도입 → KV 조회수 계산 로직을 덜어냄
- D1 도입 → KV 인덱싱 시뮬레이션을 안 해도 됨
- Workers 분리 → 배포 범위를 줄임
- 시리즈 도입 → 산발적이던 콘텐츠에 흐름을 부여
그리고 이 모든 인프라 변화에서 콘텐츠는 한 번도 건드리지 않았다. Git repo의 마크다운 파일은 GitHub Pages 시절과 동일하다. 실제로 Worker API를 전부 꺼도 npm run build만 돌리면 좋아요·대시보드·퀴즈만 빠진 채 나머지는 그대로 동작한다.
인프라 의존성은 API 레이어에만 존재하고, 콘텐츠에는 없다. Cloudflare가 내일 사라져도 마크다운과 npm run build만 있으면 블로그는 어디서든 돌아간다. 이 분리가, 4편에 걸쳐 인프라를 갈아엎으면서도 의도적으로 지킨 유일한 설계 원칙이다.
이 시리즈에서 다루지 않은 영역이 하나 남아 있다. Obsidian Vault에서 글을 꺼내 AI가 블로그 포맷으로 변환하고, 6개 AI 모델이 병렬로 리뷰한 뒤 PR로 발행하는 콘텐츠 파이프라인이다. 이 글도 그 파이프라인을 거쳤다. 인프라가 Cloudflare 위에 있다면, 콘텐츠 파이프라인은 로컬 머신과 GitHub 위에 있다 — 관심이 있다면 별도 글로 다룰 수 있을 것이다.