로그인 없는 정적 사이트에서 사용자를 어떻게 구분하는가
목차
정적 사이트에서 로그인 없이 “같은 브라우저인지” 구분하는 세 가지 방법과 선택 기준. localStorage UUID부터 Browser Fingerprinting까지, 각 방식이 제공하는 것과 제공하지 못하는 것을 비교한다.
정적 사이트에 좋아요 버튼을 만들면 반드시 부딪히는 문제가 있다. “이 브라우저가 이미 눌렀는지” 어떻게 아는가. 서버 세션이 없고, 로그인도 없다. GitHub Pages에 동적 기능을 구현하면서 좋아요와 조회수를 만들었고, 퀴즈 시스템을 추가하면서 도전자 구분까지 필요해졌다.
여기서 먼저 짚어야 할 것이 있다. 이 글에서 “사용자 구분”이라 부르는 것은 로그인 수준의 identity가 아니다. 정확히는 pseudo ID — 같은 브라우저에서 온 요청인지 구분하는 정도다. 시크릿 모드나 기기를 바꾸면 새 사용자로 카운트되며, “이 사람이 누구인지”를 아는 것과는 거리가 멀다. 이 한계를 인지한 상태에서, 정적 사이트에서 선택할 수 있는 세 가지 방법을 비교한다.
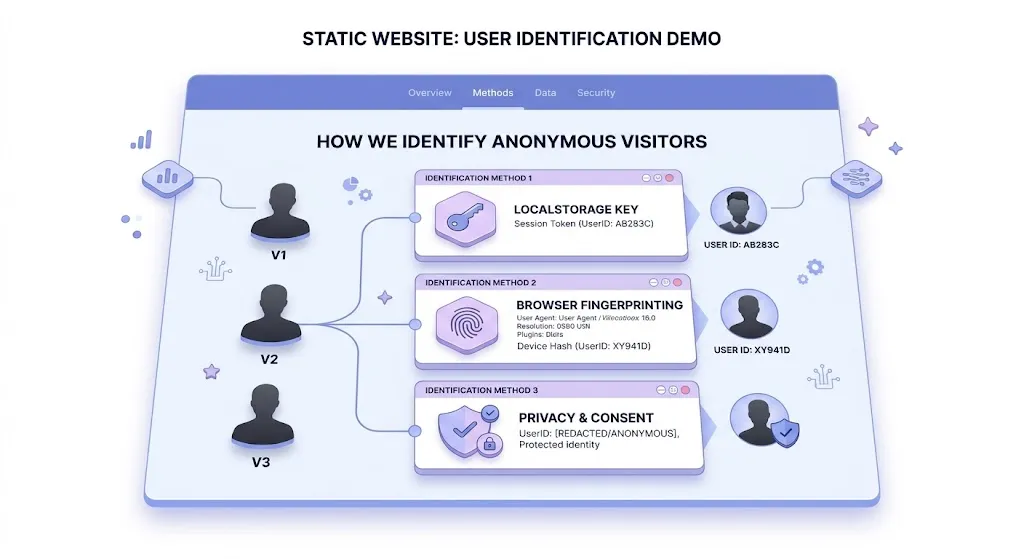
방법 1: localStorage UUID — 가장 단순한 접근
crypto.randomUUID()로 UUID v4를 생성하고 localStorage에 저장한다. 같은 브라우저에서는 항상 같은 ID가 반환되므로, 요청 헤더로 서버에 전달하면 좋아요 중복 방지와 퀴즈 도전자 구분에 사용할 수 있다.
장점: 구현이 간단하고(5줄), 같은 브라우저 내에서는 100% 일관된 구분이 가능하다.
한계: 시크릿 모드, 캐시 초기화, 다른 브라우저/기기에서는 새 ID가 생성된다. 사용자가 삭제할 수 있다는 점은 프라이버시 측면에서는 장점이기도 하다.
방법 2: IP 해시 — 서버 사이드 fallback
클라이언트가 UUID를 보내지 못하는 경우(봇, 비정상 요청)를 대비해 CF-Connecting-IP를 해시한 값을 fallback으로 사용한다.
장점: 클라이언트 협조 없이 서버 단독으로 동작한다.
한계: NAT 뒤의 사용자들이 같은 해시를 갖는다. 동적 IP 환경에서는 같은 사용자가 다른 해시를 갖는다. 단독 구분자로 쓰기엔 부정확하지만, UUID의 보조 수단으로는 충분하다.
이 블로그에서는 1번(UUID)을 주 구분자로, 2번(IP 해시)을 fallback으로 조합하고 있다. 대시보드를 Cloudflare Web Analytics로 이관하면서, Cloudflare가 내부적으로 사용하는 visitor 구분자를 빌려 쓸 수 있지 않을까 검토했지만, Cloudflare는 프라이버시 우선 설계로 visitor ID를 외부에 제공하지 않는다. 쿠키·localStorage를 사용하지 않고, IP도 즉시 폐기한다. 결국 트래픽 집계는 Cloudflare에, 사용자 행동 상태(좋아요, 퀴즈)는 자체 구분자에 맡기는 역할 분리가 성립한다.
방법 3: Browser Fingerprinting — 저장 없이 구분하는 기술
그렇다면 localStorage에 의존하지 않으면서 브라우저를 구분하는 방법은 없을까? Browser Fingerprinting이 바로 그 접근이다. 쿠키도 localStorage도 없이, 브라우저와 기기가 가진 고유한 특성들을 조합하여 “디지털 지문”을 만든다. 핵심을 먼저 짚자면, Browser Fingerprint는 authentication이 아니다. heuristic stateless identifier다. 로그인처럼 “이 사람이 누구인지” 증명하는 것이 아니라, 상태 저장 없이 “이 브라우저를 전에 본 적 있는 것 같다”고 추정하는 것이다.
Canvas 렌더링이 대표적이다. 동일한 텍스트를 Canvas에 그리면, GPU와 폰트 렌더링 엔진, 안티앨리어싱 처리 방식이 기기마다 달라서 픽셀 단위로 미세한 차이가 생긴다. 여기에 WebGL 렌더러 정보, 설치된 폰트 목록, 화면 해상도, 타임존, User-Agent 등 10~20개 특성을 조합하면, 저장하는 것이 아니라 매번 다시 계산해도 같은 결과가 나오는 구조다. 시크릿 모드에서도 동일한 값이 생성된다.
해시와의 모순: 특성이 변해도 같은 값이 나오는 원리
여기서 흥미로운 의문이 생긴다. 해시 함수는 입력이 1비트만 달라도 완전히 다른 출력을 만든다(avalanche effect: 눈사태 효과). 그런데 fingerprinting은 화면 해상도가 바뀌어도, User-Agent가 업데이트되어도 같은 브라우저로 구분한다. 이것은 해시의 본질과 모순된다.
실제로 고정밀 fingerprinting은 단순 해시가 아니라 두 가지 기법을 조합한다.
Fuzzy matching — 특성별 가중치를 두고 유사도 점수로 비교한다. 해상도가 바뀌어도 나머지 15개 특성이 같으면 동일 브라우저로 판정한다. 해시 비교가 아니라 벡터 유사도에 가깝다. 알고리즘적으로는 Locality Sensitive Hashing(LSH)이나 SimHash 같은 유사도 보존 해시가 이 영역의 기법이다 — 유사한 입력이 유사한 출력을 만들도록 설계된 해시로, 일반 암호학적 해시의 avalanche effect와 정반대 목표를 갖는다.
특성 분류 — 잘 변하는 특성(User-Agent, 화면 크기)과 잘 안 변하는 특성(Canvas, WebGL, 폰트)을 구분하여, 안정적인 특성에 높은 가중치를 부여한다.
유료 서비스에서는 여기에 서버 사이드 ML이 추가된다. 클라이언트에서 수집한 특성을 서버로 전송하면, 과거 방문의 fingerprint 프로필과 대조하여 확률적으로 동일 브라우저를 판정한다. 정확한 표현은 “해시로 고유 식별”이 아니라 “특성 벡터의 유사도로 확률적 구분”이다.
이 분야의 대표 라이브러리는 FingerprintJS(v5.1.0, MIT)다. 2012년 오픈소스 사이드 프로젝트로 시작해, 정확도 차이(오픈소스 ~60% vs 유료 99.5%, 벤더 주장)로 유료 전환을 유도하는 모델로 총 $77M 투자를 유치했다. 사기 방지, 봇 탐지, 다중 계정 방지가 주요 시장이다.
브라우저의 대응
주요 브라우저 벤더들은 fingerprinting을 적극적으로 차단하고 있다. Safari ITP는 Canvas/WebGL에 노이즈를 주입하고, Firefox ETP는 알려진 fingerprinting 스크립트를 차단한다. Chrome은 Privacy Sandbox를 통해 3자 쿠키 제거와 Topics API를 추진했으나, 2025년 4월 공식 중단했다. 장기적으로 fingerprinting의 정확도와 지속 가능성은 브라우저 벤더들의 정책 변화에 달려 있다.
장점: localStorage 삭제, 시크릿 모드에도 동일 구분이 가능하다. 클라이언트 저장소에 의존하지 않는다.
한계: 정확도가 환경에 따라 크게 달라진다(무료 ~60%). 브라우저 업데이트로 fingerprint가 변할 수 있다. GDPR에서 “삭제 불가능한 구분자”로 간주되어 프라이버시 부담이 크다.
프라이버시: 방식별 GDPR 영향
사용자를 구분하는 행위는 프라이버시와 직결된다.
| 방식 | GDPR 성격 | 동의 필요 여부 |
|---|---|---|
| localStorage UUID | persistent 구분자, 사용자 삭제 가능 | 목적에 따라 판단 필요 |
| IP 해시 | 서버 사이드, 간접 구분 | 정당한 이익 근거 가능 |
| Fingerprinting (무료) | 삭제 불가 구분자 생성 | 명시적 동의 필요 가능 |
| Fingerprinting (유료) | 제3자 위탁 + 삭제 불가 구분자 | 동의 + DPA 필요 |
localStorage UUID도 GDPR 관점에서 주의가 필요하다. persistent ID는 서버 로그와 결합되면 재식별 가능성이 생기며, 관할권에 따라 쿠키와 유사한 수준의 고지·동의 의무가 적용될 수 있다. 비상업적 개인 블로그에서 익명 UUID로 좋아요 중복만 방지하는 용도라면 “정당한 이익(legitimate interest)“으로 해석할 여지가 있지만, 확정적인 면제는 아니다.
Fingerprint Inc.는 “광고 추적”이 아닌 “사기 방지(fraud prevention)“로 포지셔닝하여 정당한 이익 근거를 확보했다. 이 전략은 사기 방지라는 목적이 명확할 때만 성립한다.
선택 기준: 어떤 조건에서 어떤 방식을 쓸 것인가
세 가지 방식의 trade-off를 정리하면 다음과 같다.
| 방식 | 구분 정확도 | 프라이버시 부담 | 구현 복잡도 | 적합 시나리오 |
|---|---|---|---|---|
| localStorage UUID | 단일 브라우저 100% | 낮음 | 최소 | 개인 블로그, 소규모 서비스 |
| + IP 해시 fallback | 보조 수단 | 낮음 | 낮음 | UUID 미전송 대비 |
| 완전 익명 집계 | 구분 불가 | 없음 | 최소 | 구분 불필요한 통계 |
| Fingerprinting (무료) | ~60% (벤더 주장) | 높음 | 중간 | 보조 구분자, PoC |
| Fingerprinting (유료) | 99.5% (벤더 주장) | 매우 높음 | 높음 (제3자 의존) | 사기 방지, 계정 보안 |
| 로그인 | 100% | 동의 기반 | 높음 | 정확도가 비즈니스 요구사항 |
이 표를 의사결정에 적용하려면 다음 질문을 순서대로 따라가면 된다.
- 구분이 아예 필요 없는가? → 완전 익명 집계. 트래픽 통계만 필요하면 Cloudflare Web Analytics만으로 충분하다
- “같은 브라우저에서 중복 방지” 정도면 충분한가? → localStorage UUID + IP 해시. 대부분의 정적 사이트, 개인 블로그가 여기에 해당한다
- 시크릿 모드/캐시 초기화에서도 구분이 필요한가? → Fingerprinting. 단, 무료 60%의 정확도와 프라이버시 부담을 감수할 수 있는지 판단이 필요하다
- 구분 정확도가 비즈니스에 직접 영향을 미치는가? (사기 방지, 과금 등) → 로그인 또는 Fingerprinting 유료. 이 시점에서는 정적 사이트의 범위를 넘어선다
대부분의 경우 2번에서 끝난다. “같은 브라우저에서 중복을 막는다”는 목적에 localStorage UUID는 과하지도, 부족하지도 않다. 그리고 식별 대상이 반드시 사람일 필요도 없다 — stateless 환경에서 요청을 보내는 주체가 사람인지 자동화된 에이전트인지를 구분하는 문제도 결국 같은 구조 위에 있다.
정리
정적 사이트에서 로그인 없이 사용자를 완벽히 구분하는 것은 구조적으로 불가능하다. 하지만 목적에 맞는 수준의 구분은 가능하다.
이 글에서 가져갈 수 있는 판단 기준은 세 가지다.
- 구분의 수준을 정의하라 — “같은 브라우저 구분”과 “사용자 식별”은 다른 문제다. 대부분의 정적 사이트는 전자면 충분하다
- 정확도와 프라이버시는 trade-off다 — fingerprinting은 localStorage의 한계(시크릿 모드, 캐시 초기화)를 해결하지만, “삭제할 수 없는 구분자”라는 프라이버시 부담이 따른다. 어느 쪽이 더 중요한지는 서비스 성격에 따라 다르다
- 해시의 반대편에도 해시가 있다 — avalanche effect를 목표로 하는 암호학적 해시와, 유사한 입력에 유사한 출력을 만드는 LSH는 정반대 설계 목표를 갖는다. 같은 “해시”라는 이름 아래 전혀 다른 문제를 푸는 기법이 존재한다는 것은, 다른 기술 선택에서도 적용할 수 있는 관점이다
이 접근은 실 사용자뿐 아니라 AI Agent 식별에도 활용될 수 있다. 특히 stateless 환경에서 crawler, automation agent, AI tool 호출 등을 구분하기 위한 가벼운 agent identity로 확장 가능성이 있다.